篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
CSS选择器
html中为指定元素指定显示效果,比如颜色,背景,字体等不同的属性,这些样式都是通过css选择器告诉浏览器指定样式风格。
| 表达式 | 含义 |
|---|---|
| #animal | 获取id为animal的所有元素 |
| .animal | 获取class为animal的所有元素 |
| a.active | 获取类为active的a标签 |
| .animal > .pig | 获取类animal直接子元素中类为.pig的元素 |
| .animal .pig | 获取类animal后代元素中类为.pig的元素 |
| a[href*=”animal”] | 获取包含类animal的a元素 |
| a[href^=”http”] | 获取href以http开头的a元素 |
| a[href$=”gov.cn”] | 获取href以gov.cn结尾的a元素 |
| div[class=”animal”][ctype=”pig”] | 获取多属性同时具备的元素 |
| div > a:nth-child(2) | 获取div下的第二个a元素 |
| .pig , .animal | 同时选择两个class的所有元素 |
| p:nth-last-child(1) | 获取倒数第一个p元素 |
| p:nth-child(even) p:nth-child(odd) | 获取奇数偶数节点 |
| h3 + span | 获取h3 后面紧跟着的兄弟节点 span |
| h3 ~ span | 获取h3 后面所有的兄弟节点 span |
实战
链家
目标抓取网站:https://su.lianjia.com/ershoufang/pg
抓取内容:分页抓取二手房的标题,地址,信息,关注量,标签,总价,单价等
分析
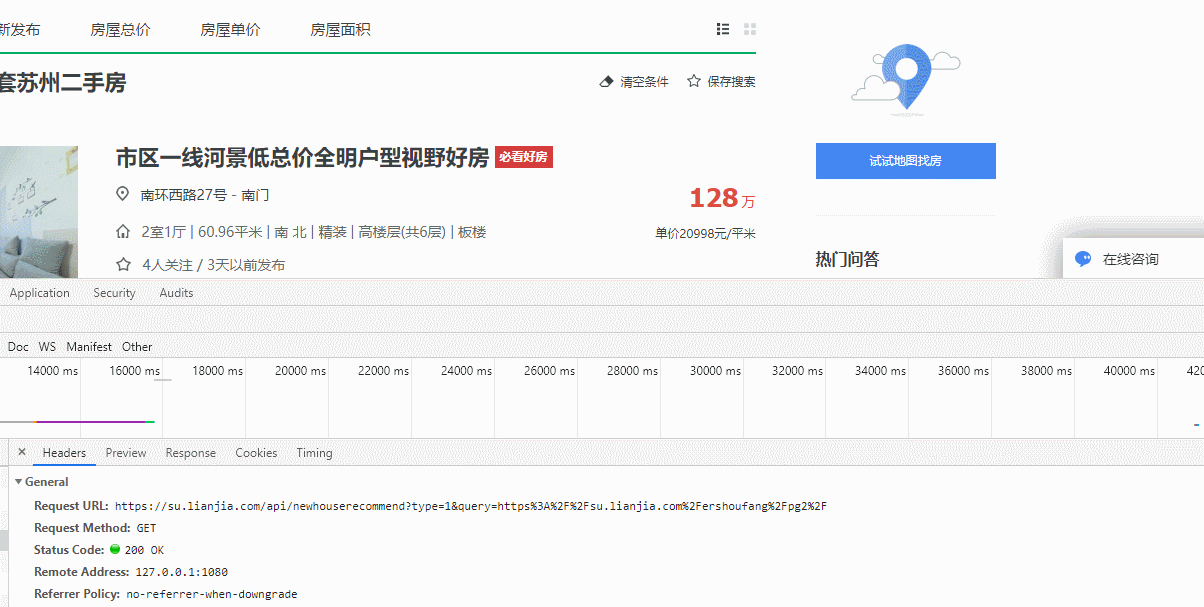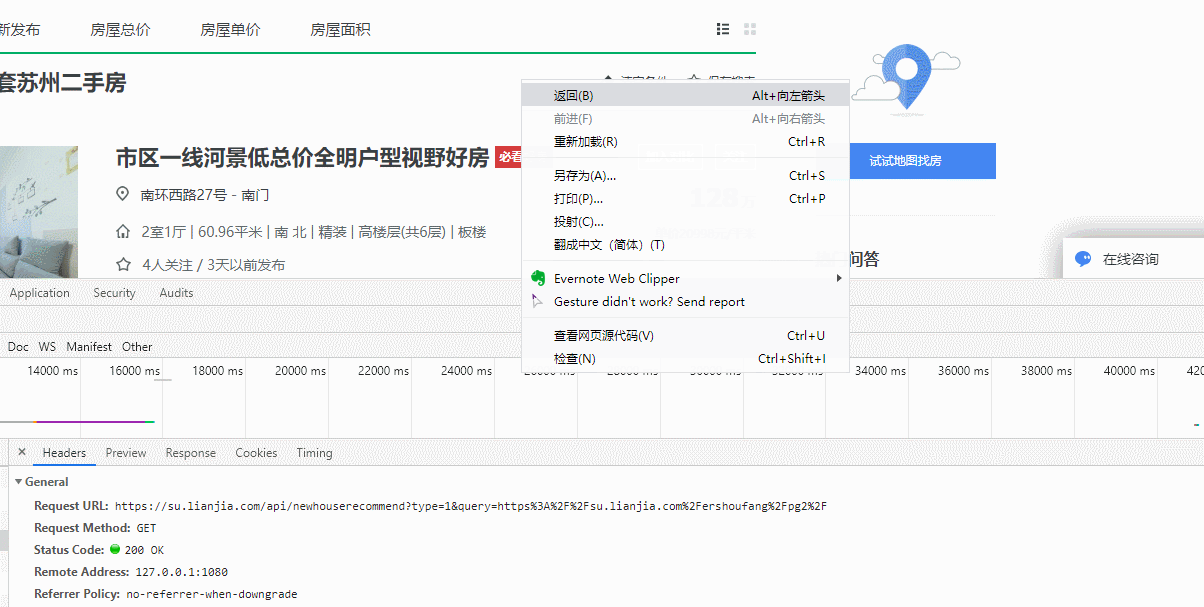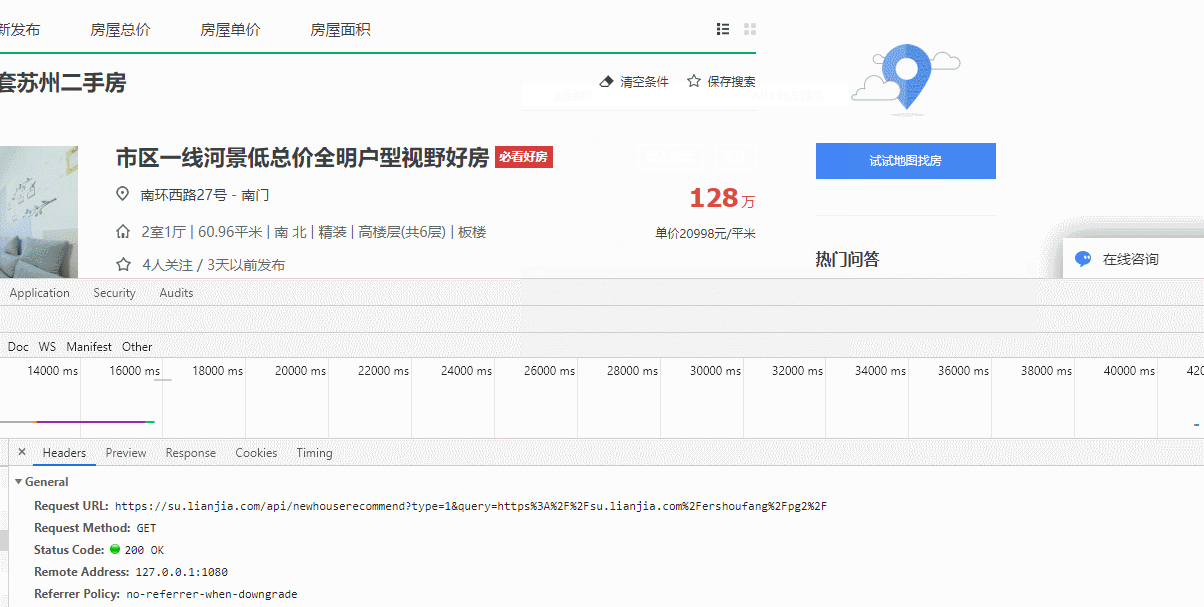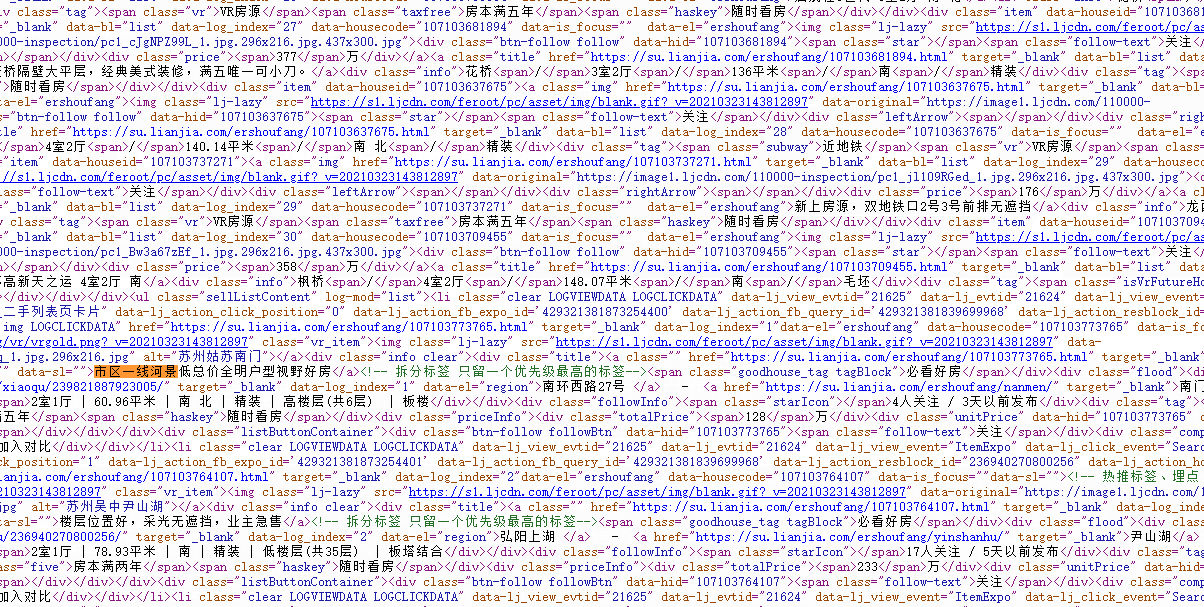
通过获取网页源代码发现所有的二手房信息都直接渲染在页面上,那么可以直接请求页面地址分析二手房源码后,通过parsel库parsel.Selector(html_data)转为我们可以使用选择器分析的对象。
通过css选择器.clear.LOGCLICKDATA拿到所有的二手房信息所在的li元素
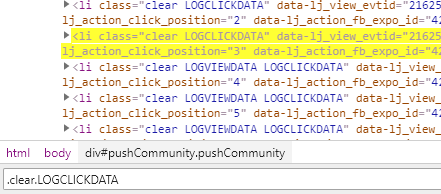
在li元素下可以css选择器获取所有的.title a::text标题,.positionInfo a::text地址,.followInfo::text关注量等信息。
1 | selector = parsel.Selector(html_data) |
爬取完成
点击下一页的时候,页面url添加了路径参数pg{},那么可以通过加该字段实现分页抓取。

猫眼电影
分析
目标抓取网站:https://maoyan.com/board
抓取内容:热映口碑榜的电影名,主演,上映时间等。
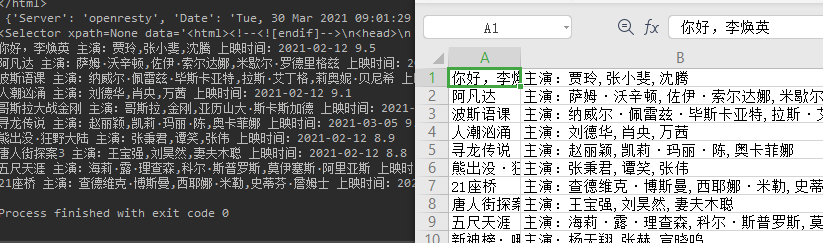
老规矩,查看网页源代码电影数据完整返回给前端,没有做异步请求。那么直接访问猫眼的热映口碑榜通过parsel库解析成Selector对象,开始利用css选择器分析页面字段。
通过控制台源码发现类.board-wrapper下dd元素包含了所有的电影信息,那么遍历其下的标签列表根据css选择器筛选拿到需要的数据即可。
1 | selector = parsel.Selector(html_data) |
爬取完成
喜马拉雅
分析
目标网站:https://www.ximalaya.com/xiangsheng/9723091
抓取内容:下载当前主题的所有页面的音频文件。
老规矩,查看网页源代码发现所有的音频标签会在当前页面ur后添加音频的id跳转到一个新的页面,如:https://www.ximalaya.com/xiangsheng/9723091/45982355
点击播放后,控制台的Media出现请求的音频地址,如:https://aod.cos.tx.xmcdn.com/group31/M01/36/04/wKgJSVmC6drBDNayAh_Q8WincwI414.m4a
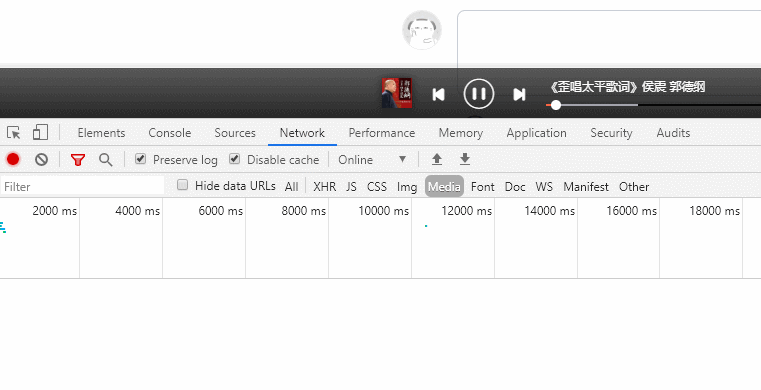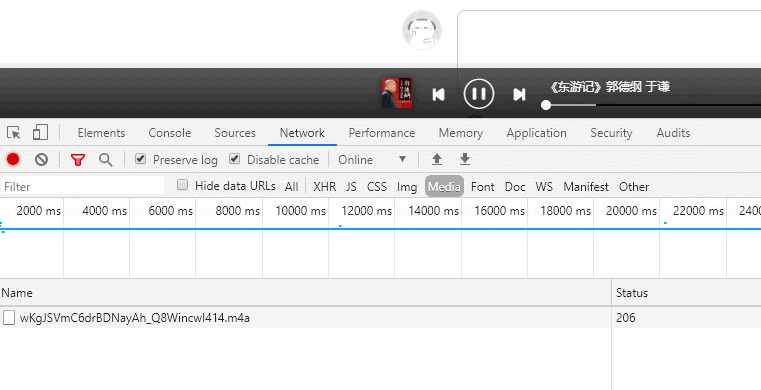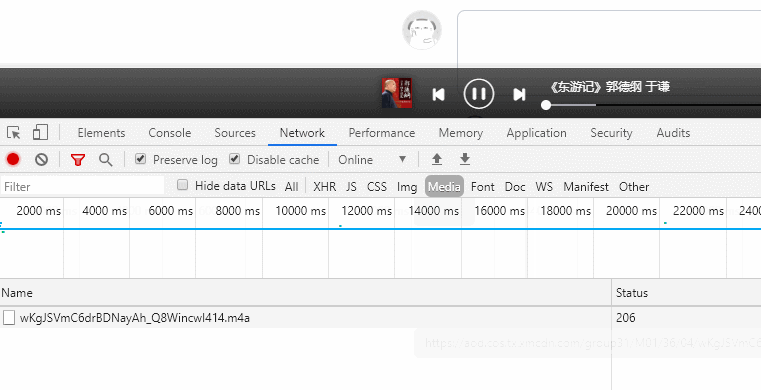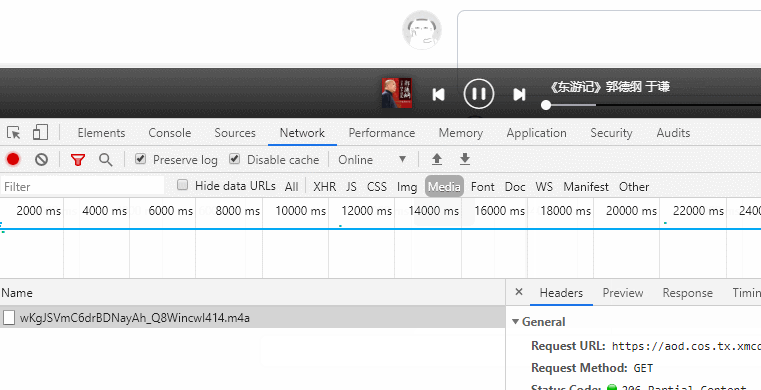
通过控制台搜索音频关键字段,找到返回音频地址的请求https://www.ximalaya.com/revision/play/v1/audio?id=46106992&ptype=1
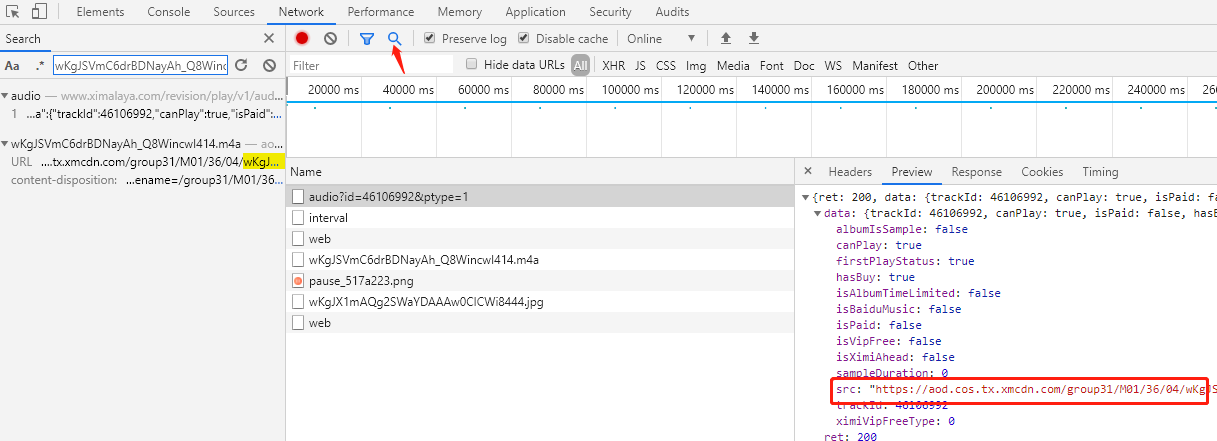
该请求参数由音频id和ptype=1组成,通过css选择器.sound-list li.lF_ a::attr(href)分析列表页的音频的href拿到音频id,通过css选择器.sound-list li.lF_ a::attr(title)拿到音频标题。点击下一页发现只是在原url后添加p{page}字段,综上通过open函数写入音频文件完成下载。
1 | titles = selector.css('.sound-list li.lF_ a::attr(title)').getall() |
爬取完成
XPATH选择器
XPath (XML Path Language) 是由国际标准化组织W3C指定的,用来在 XML 和 HTML 文档中选择节点的语言。目前主流浏览器 (chrome、firefox,edge,safari) 都支持XPath语法,xpath有 1 和 2 两个版本,目前浏览器支持的是 xpath 1的语法,且比CSS选择器功能更强大。
| 表达式 | 含义 |
|---|---|
| /html/body/div | 选择根节点html下面的body下面的div元素,/从子节点找,//从所有子节点包括子节点的子节点中找 |
| //div/* | 所有div节点下所有元素 |
| //*[@id=’west’] | id为west的元素 |
| //select[@class=’single_choice’] | class为single_choice的select元素 |
| //p[@class=”capital huge-city”] | 多元素组合选择 |
| //*[@multiple] | 具有multiple属性的元素 |
| //*[contains(@style,’color’)] | style包含color的元素 |
| //*[starts-with(@style,’color’)] | 以style是color开头的元素,//*[ends-with(@style,’color’)]结尾元素 |
| //div/p[2] | 所有div下的第二个p标签 |
| //p[last()] | 最后一个p元素 |
| //div/p[last()-2] | 所有div下倒数第三个p元素 |
| //option[position()<=2] | option类型的第1-2个元素 |
| //*[@class=’multi_choice’]/*[position()>=last()-2] | 选择class属性为multi_choice的后3个子元素 |
| //option|//h4 | 所有的option元素 和所有的 h4 元素 |
| //*[@id=’china’]/.. | 选择 id 为 china 的节点的父节点 |
| //*[@id=’china’]/../../.. | 上上父节点 |
| //*[@class=’single_choice’]/following-sibling::div | 选择后续节点中的div节点 等同于CSS选择器.single_choice ~ * |
| //[@class=’single_choice’]/preceding-sibling:: | 前面兄弟节点 |
实战
新笔趣阁
分析
目标网站:http://www.xbiquge.la/10/10489/
抓取内容:抓取三寸人间所有章节的文章保存。
章节列表只有小说章节信息,点击每个章节跳转到章节页面,通常xpath表达式//div[@id="info"]/h1/text()拿到书籍名称,所有的章节都依赖于于id为list的div下的dl下的dd下的a标签的href属性跳转到章节页面。
拼接主域名http://www.xbiquge.la即可跳转到章节详情页面,通过xpath表达式//*[@id="content"]/text()拿到详情页面小说的完整内容
1 | # 开文件流 打开一个文件 把我们数据写入到文件中去 a是追加写入 写入完第一章就继续追加写入第二章 |
爬取完成
其实很多情况下不需要自己去分析dom节点定位css或xpath表达式,chrome已经为我们集成了插件。
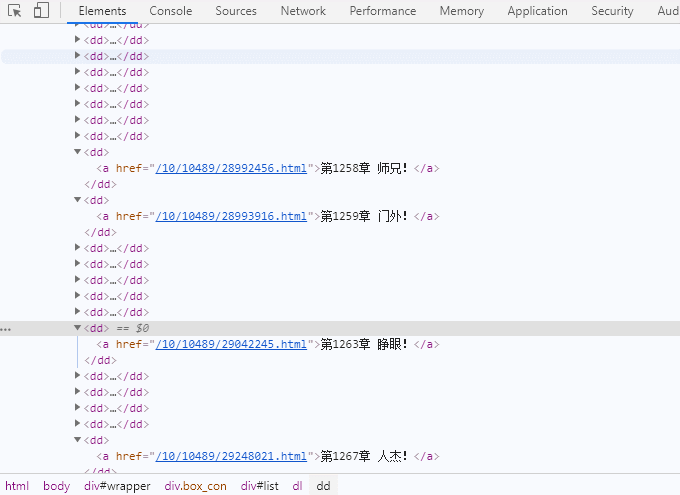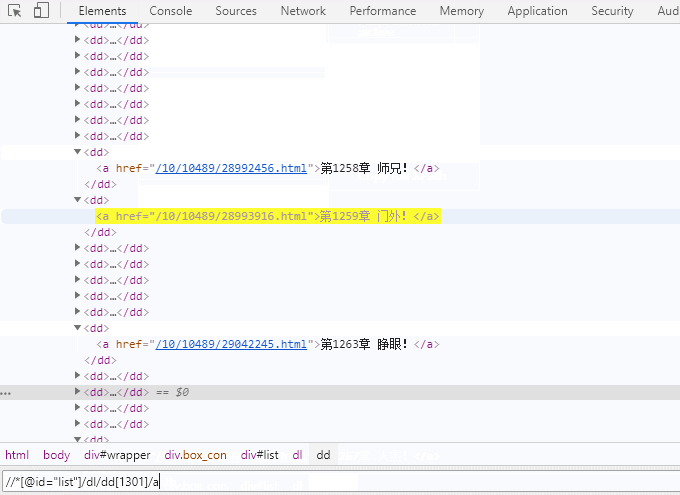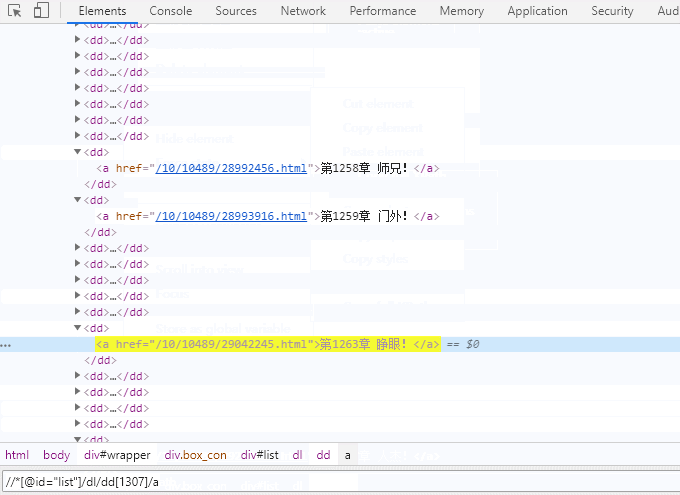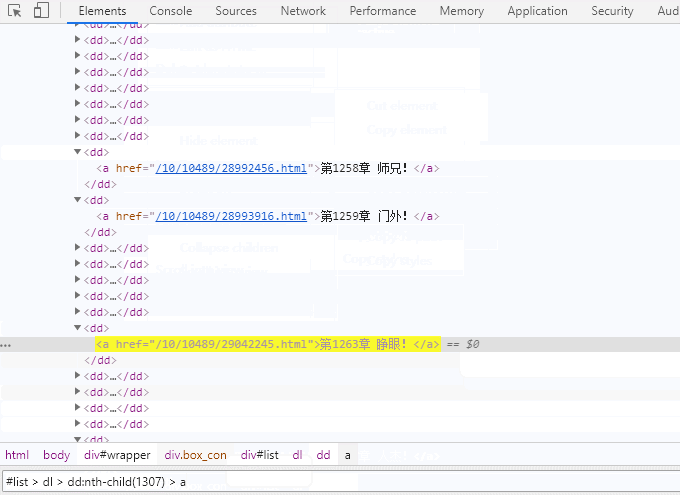
JSON
很多情况页面不直接返回html或xml文本元素,或者这些文本分析起来很困难的情况下,可以通过控制台中的xhr模式抓取后端请求回来的json数据,直接解析json即可拿到想要的数据。
实战
拉勾
分析
目标网站:https://www.lagou.com/jobs/list_C%2B%2B?labelWords=&fromSearch=true&suginput=
抓取内容:抓取首页职位地址,公司名,规模等信息保存。
搜索C++后,打开控制台将结果中的带薪年假搜索拿到实际请求路径https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false,该请求是post请求,参数如下
1 | data = { |
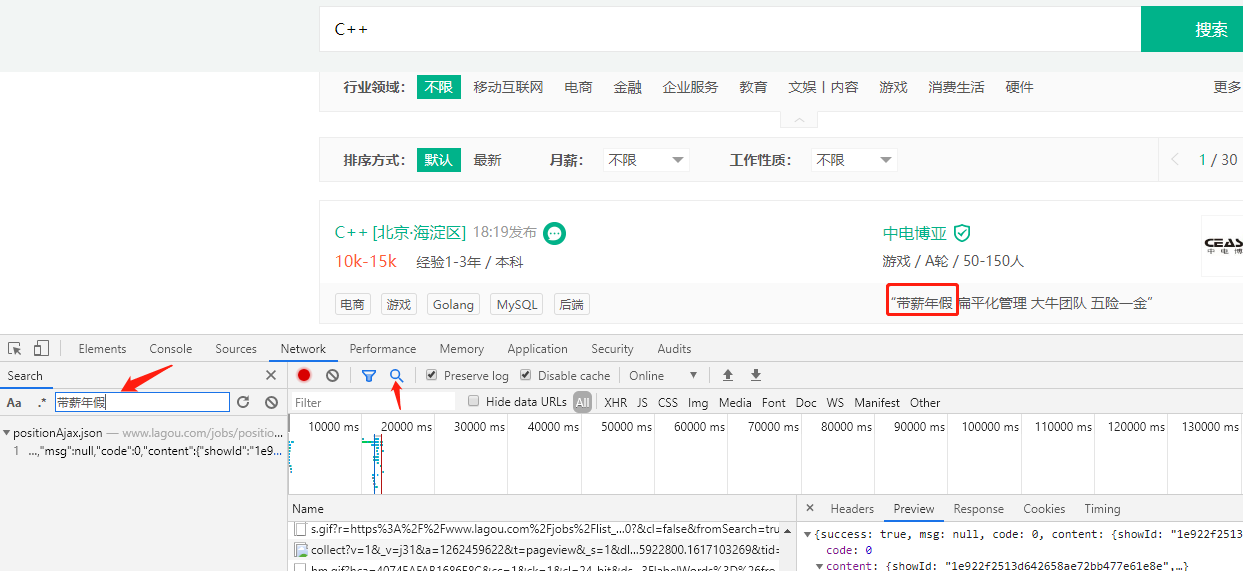
通过控制台Preview分析返回的json数据,data['content']['positionResult']['result']即为职位信息
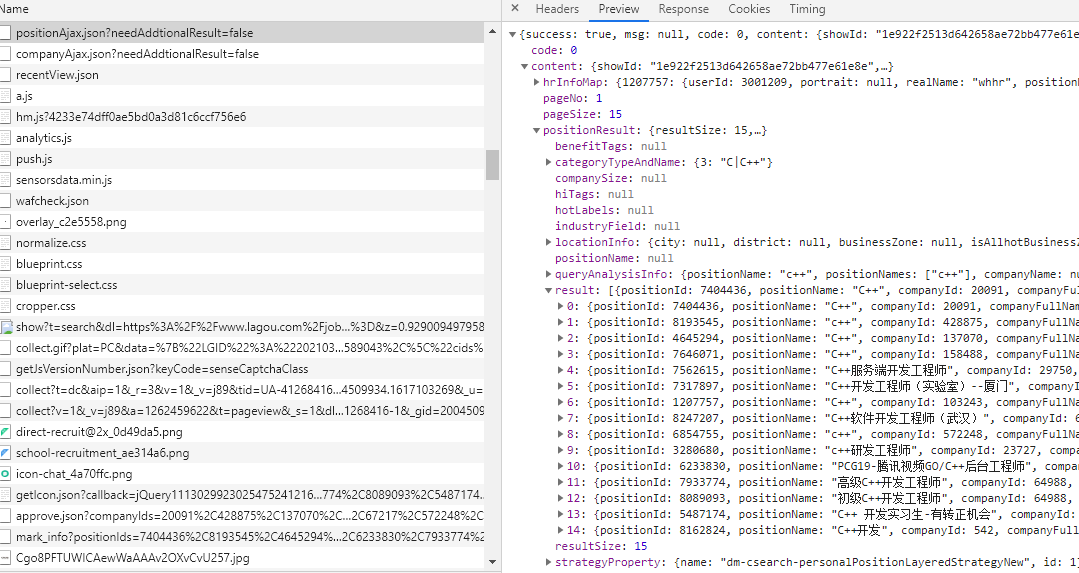
不过当我们直接请求时会报dtacess deny,可能对请求头中的参数做了校验。
1 | Traceback (most recent call last): |
我们将Cookie和User-Agent加入header后,即可以完整请求到json数据,进行数据分析。
1 | resp = requests.post(api_url, headers=headers) |
爬取完成
完整源码请关注微信公众号:ReverseCode,回复:爬虫基础

