篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
爬虫介绍
爬虫目的
- 大数据时代所谓的人工智能都需要建立海量基础的数据上,一切一切的分析都是一数据为基础核心,那么对于企业来说,合理采集数据是既节省成本同时间也可以完成业务分析的捷径。
- 企业需要大量数据进行测试,对网站或app的负载,流量,服务器的CPU进行测试,采集数据是保证大数据量业务上线正常流转的必备前提。
- 所有搜索引擎的底层都是一个个的自动化爬虫,在海量的互联网信息中进行分析处理收录。
- 各大企业都希望自己的产品搜索靠前,对于SEO来说,除了充钱,足够了解爬虫可以从原理上实现搜索引擎的工作原理,实现SEO优化。
- 从技术层面来说,爬虫虽不是成体系型的一种技术栈,不过技术涉及领域极光,包括html解析,js逆向,安卓底层逆向,汇编分析,反爬虫与反反爬虫的对抗等等,其实以上也属于网络安全层的一个方向,文明爬虫,技术无罪。
什么是最好的语言
当之无愧强类型语言Python,毋庸置疑,一来Python的三方库种类繁多且爬虫框架日新月异,请求与解析模块成熟,且拥有很多有趣的语法糖可以快速处理数据。相对于代码量臃肿的java来说语法简单,学习曲线短,因为java需要jvm虚拟机的编译成字节码的过程,对于爬虫来讲,Python免编译即可跨平台运行,且基于C++更接近底层,性能在一定程度上领超java,故优先选择python(别跟我提php)。
当然玩到最后语言只是一种实现方式而已,只是这些路都通往罗马,哪条在实际场景中更方便到达而已。比如:安卓逆向过程hook框架中,xposed和frida是我们的首选,两者各有优劣,视不同场景而定。
- Xposed是一个在andoid平台上比较成熟的hook框架,可以完美的在dalvik虚拟机上做到hook任意java方法,配置安装环境繁琐,兼容性差,无法对native层实现底层注入。
- Frida是一个跨平台的hook框架,可以hook Java和native层,且不需要每次都重启手机,需要我们手动将java的语法转为frida的实现方式,无法像Xposed用于实践生产中。
爬虫路对抗现状
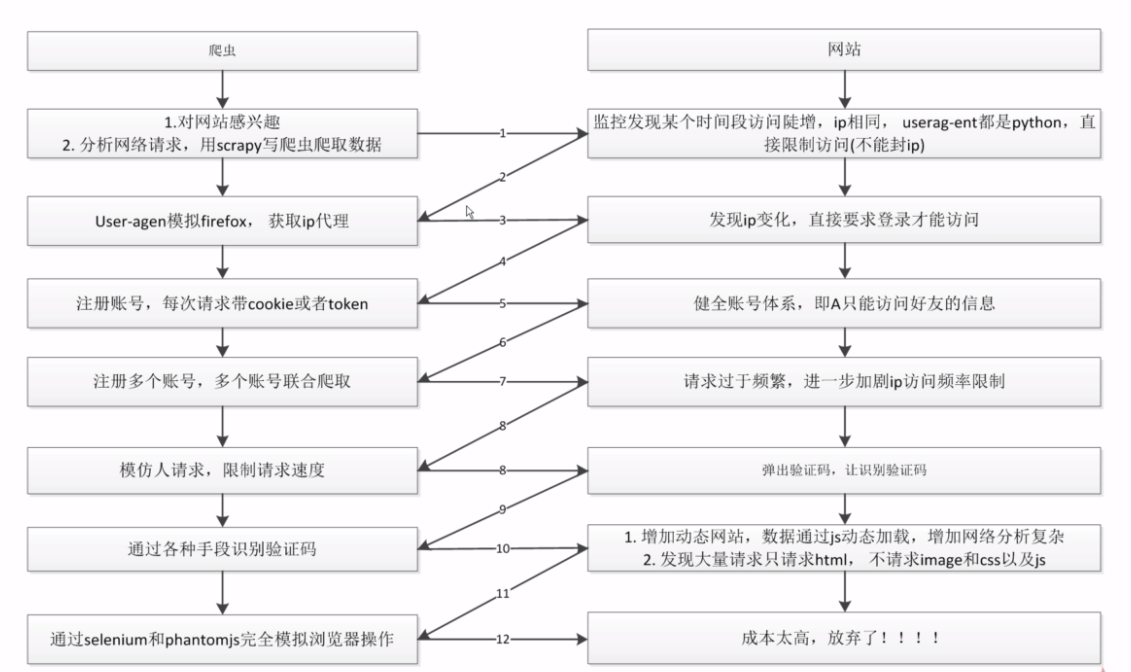
这是一张老图,当然现在很多网站在请求头中实现了对selenium,phantomjs底层的api监控,总之,道高一尺魔高一丈,攻防之间,其乐无穷。
实战
话不多说,直接开干。鲁迅曾经说过,他在爬虫生涯中超过一半的苦难均由Windows赐予,所以我建议还是用kali或者ubuntu吧,如果嫌麻烦,就退一步用centos吧,当然你用windows出现的问题需要自行google解决,基础篇目测应该不存在,用windows可以直接跳到doutula内容。
服务器搭建
这里就不聊kali或者ubuntu在虚拟机的搭建了,简单介绍一下使用vagrant创建centos虚拟机吧,
进入vagrant官网,vagrant安装好后进入镜像仓库搜索需要安装的镜像。
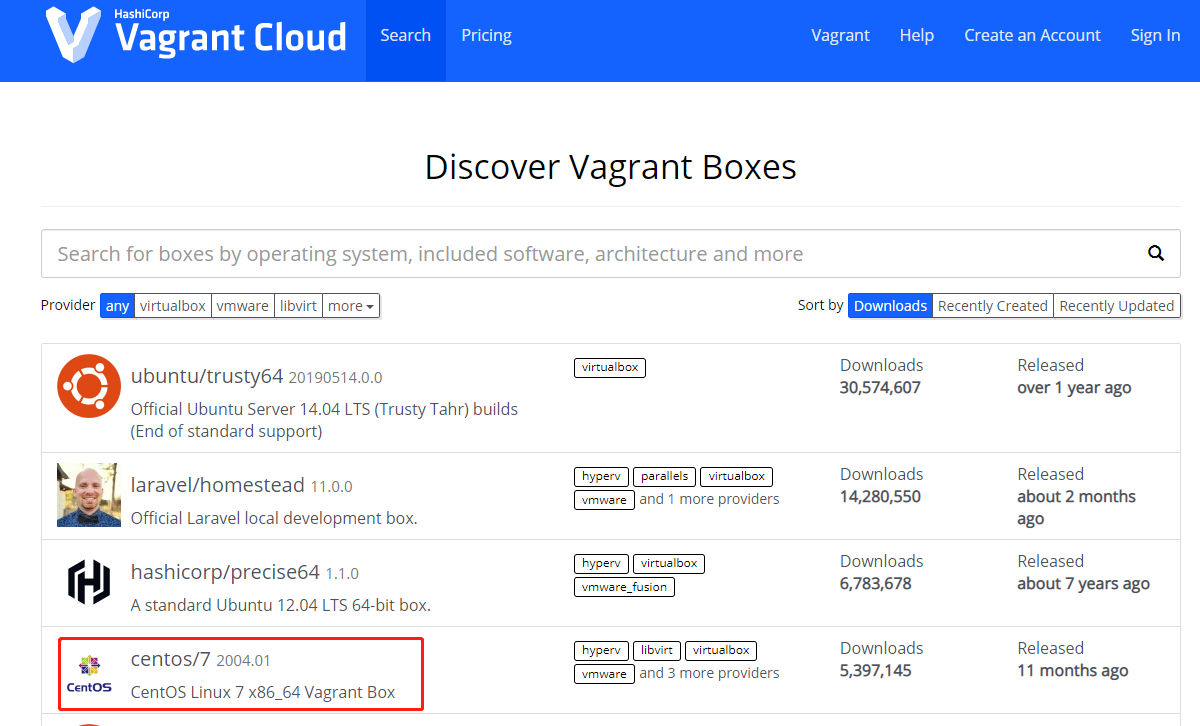
mkdir centos7 && vagrant init centos/7 && vagrant up && vagrant ssh 创建并开启镜像,自动生成Vagrantfile,默认网络nat,初始配置如下
config.vm.network "private_network", ip: "192.168.56.10"配置NAT网络,选其一即可config.vm.network "public_network", ip: "192.168.0.102"配置桥接网络yum list installed | grep openssh-server 确保安装了 openssh-server,否则yum install openssh-server
vi /etc/ssh/sshd_config 并注释
#PasswordAuthentication yes,打开Port,ListenAddress,PermitRootLoin,PasswordAuthentication执行service sshd restart实现远程连接
安装nodejs并配置淘宝源npm config set registry http://registry.npm.taobao.org/
多环境配置
由于python2已经废弃维护,往后皆基于python3实战开发。进入python官网下载python 3.7.0,或者通过清华大学源下载anaconda 5.3.1会自动下载常用库。
为了避免不同项目间引用的依赖包冲突,我们将不同项目维护不同的环境。
1 | yum install -y wget zlib-devel gcc bzip2-devel openssl-devel libffi-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel net-tools ftp vsftpd 安装常用包 |
1 | pip3 install --upgrade pip |
doutula
这是一个表情包网站,本次就以本网站的最新表情页面作为案例。
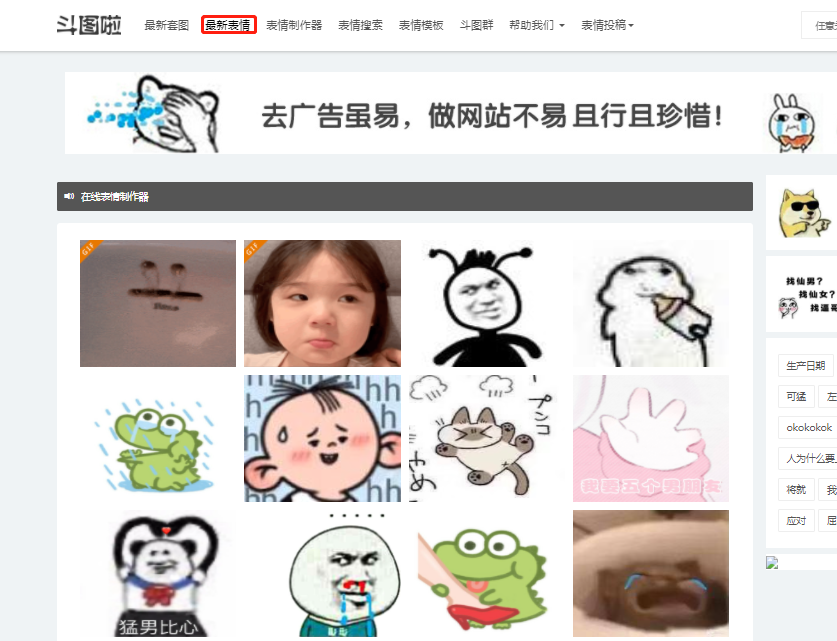
ctrl+u获取网页源代码,发现本页面所有的表情包都以html表情直接显示在页面上,那么只需要使用requests库请求URL,parsel库来解析页面,通过xpath或者css选择器获取页面元素。
通过点击分页,该页面的url会跳转时添加page参数,从https://www.doutula.com/photo/list/变成https://www.doutula.com/photo/list/?page=2,重新向服务器发起请求。
1 | import requests |
打印出来的结果是b'<html>\r\n<head><title>404 Not Found</title></head>\r\n<body bgcolor="white">\r\n<center><h1>404 Not Found</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n',说明做了反爬,可能对请求头的参数做了校验。先尝试将User-Agent加入请求头中,再次发起请求。
1 | import requests |
果然将页面内容完整打印出来,所有的图片地址也都明文显示在页面上。通过分析页面上的图片元素的dom节点,所有的图片节点都存在于类col-xs-6 col-sm-3的a标签下的img元素,通过xpath表达式可以取出这些元素下的属性,包括图片地址data-original,说明alt等。
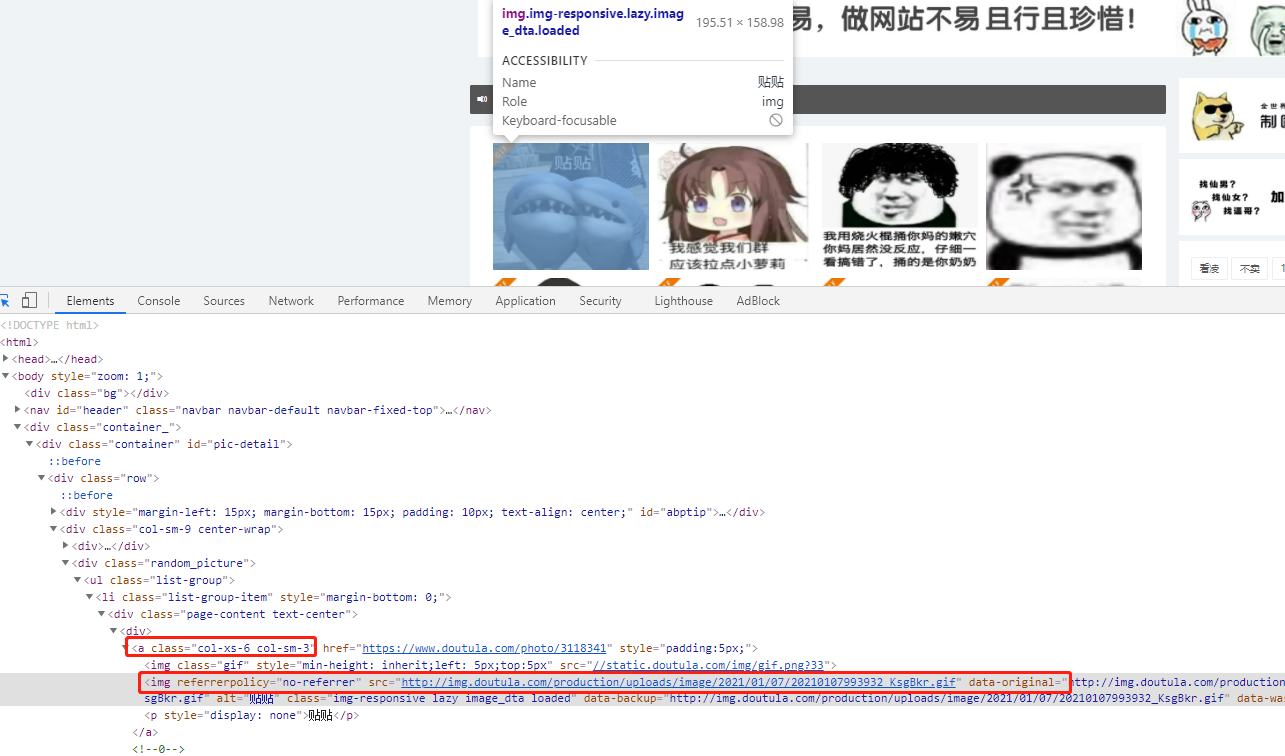
1 | for page in range(1,3466): |
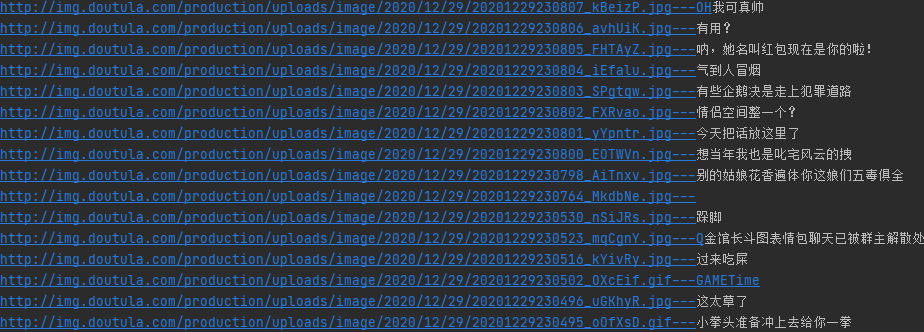
接下来在通过IO流将图片存储到本地完成基础图片爬取。
完整源码请关注微信公众号:ReverseCode,回复:爬虫基础

