篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
_search解析
1 | GET /_search |
took:整个搜索请求花费了多少毫秒
hits.total:本次搜索,返回了几条结果
hits.max_score:本次搜索的所有结果中,最大的相关度分数是多少,每一条document对于search的相关度,越相关,_score分数越大,排位越靠前
hits.hits:默认查询前10条数据,完整数据,_score降序排序
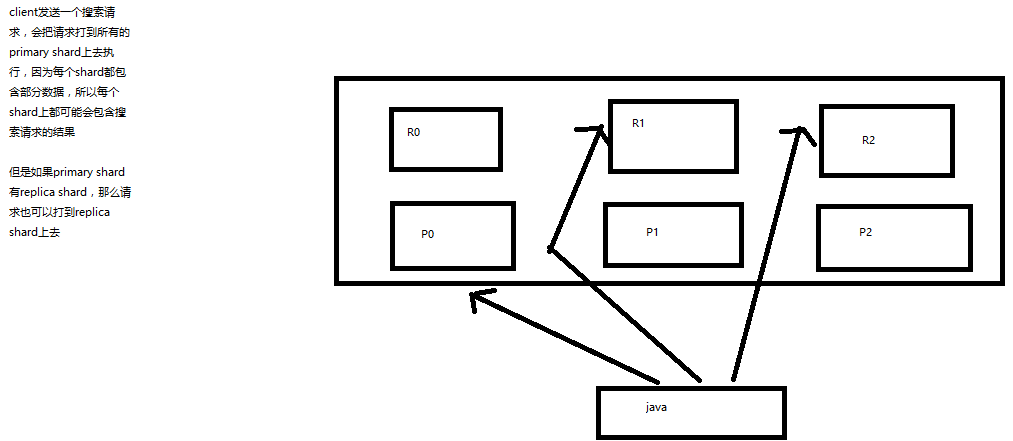
shards:shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
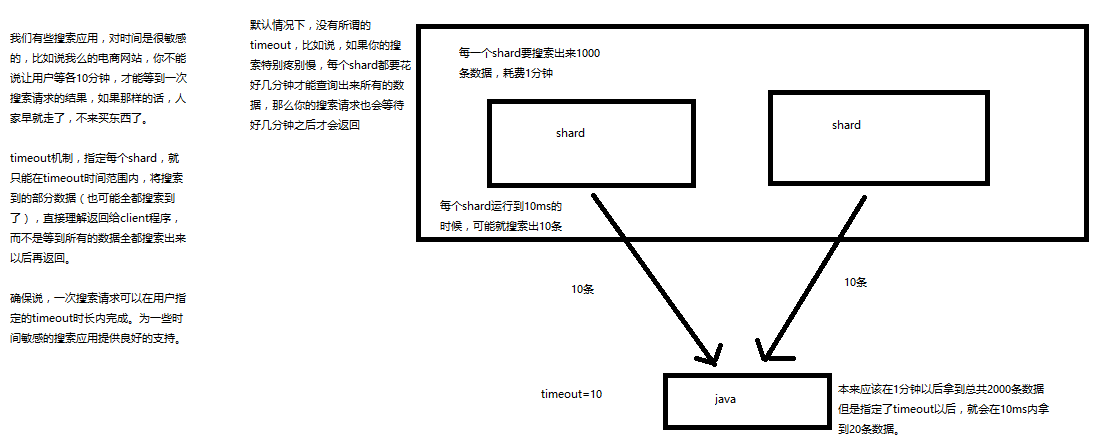
timeout:默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制
timeout=10ms,timeout=1s,timeout=1m
GET /_search?timeout=10m
搜索模式解析
multi-index和multi-type搜索模式
1 | /_search:所有索引,所有type下的所有数据都搜索出来 |
- exact value
2017-01-01,exact value,搜索的时候,必须输入2017-01-01,才能搜索出来,如果你输入一个01,是搜索不出来的
- full text
(1)缩写 vs. 全程:cn vs. china
(2)格式转化:like liked likes
(3)大小写:Tom vs tom
(4)同义词:like vs love
2017-01-01,2017 01 01,搜索2017,或者01,都可以搜索出来
china,搜索cn,也可以将china搜索出来
likes,搜索like,也可以将likes搜索出来
Tom,搜索tom,也可以将Tom搜索出来
like,搜索love,同义词,也可以将like搜索出来
就不是说单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)进行匹配,也可以通过缩写、时态、大小写、同义词等进行匹配。
倒排索引
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.
mother like little dog,不可能有任何结果
normalization,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率,包括时态的转换,单复数的转换,同义词的转换,大小写的转换。
| word | doc1 | doc2 |
|---|---|---|
| I | * | * |
| really | * | |
| like | * | * |
| my | * | * |
| little | * | |
| dog | * | * |
| and | * | |
| think | * | |
| mom | * | * |
| also | * | |
| them | * | |
| He | * | |
| never | * | |
| any | * | |
| so | * | |
| hope | * | |
| that | * | |
| will | * | |
| not | * | |
| expect | * | |
| me | * | |
| to | * | |
| him | * |
分词器
切分词语,normalization(提升recall召回率),将句子拆分成一个一个的单个的单词,同时对每个单词进行normalization(时态转换,单复数转换),分词器。
recall召回率:搜索的时候,增加能够搜索到的结果的数量
1 | character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(<span>hello<span> --> hello),& --> and(I&you --> I and you) |
内置分词器
Set the shape to semi-transparent by calling set_trans(5)
1 | standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard) |
分页搜索
es进行分页搜索
size,from
1 | GET /_search?size=10 |
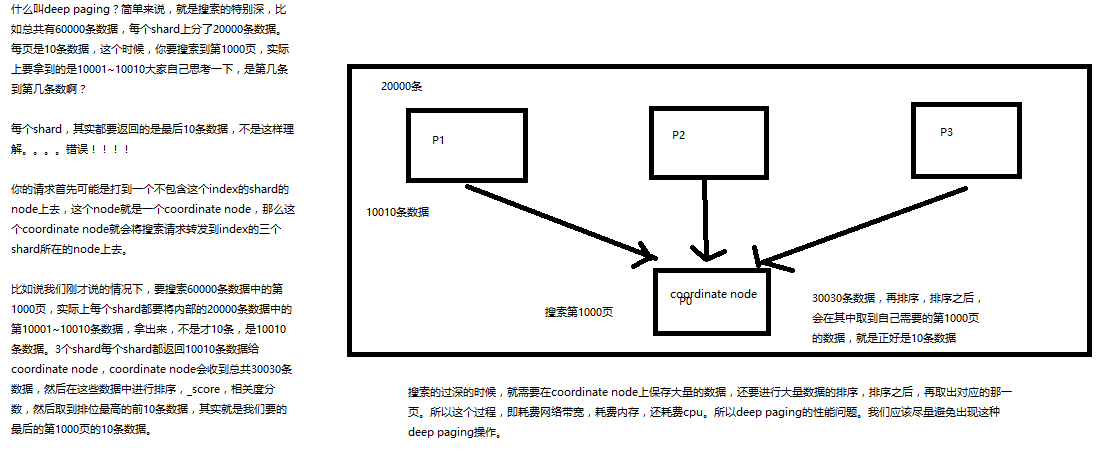
deep paging
query string
1 | GET /test_index/test_type/_search?q=test_field:test 包含 |
es中的_all元数据,在建立索引的时候,我们插入一条document,它里面包含了多个field,此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_all field的值,同时建立索引,后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索_all field,其中是包含了所有field的值的。
1 | { |
jack 26 jack@sina.com guangzhou,作为这一条document的_all field的值,同时进行分词后建立对应的倒排索引
mapping
插入几条数据,让es自动为我们建立一个索引
1 | PUT /website/article/1 |
dynamic mapping,自动为我们建立index,创建type,以及type对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置
1 | GET /website/_mapping/article |
因为es自动建立mapping的时候,设置了不同的field不同的data type。不同的data type的分词、搜索等行为是不一样的。所以出现了_all field和post_date field的搜索表现完全不一样。

