篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
需求
继爬虫基础篇之Scrapy抓取京东之后,我们对scrapy有了一定的掌握,接下来通过多渠道汇总对失信人信息抓取入库。
- 抓取百度失信人名单
- 抓取最高人民法院失信人名单
- 抓取国家企业信用公示系统失信人公告
- 把上面三个来源的失信人信息进行合并,去重
目标
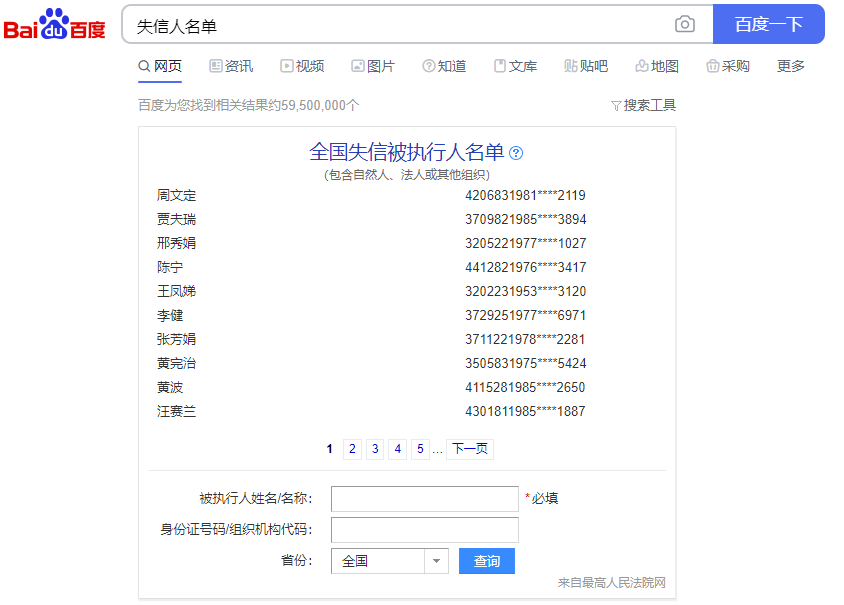
百度
搜索失信人名单
抓取数据: 失信人名称, 失信人号码,法人(企业), 年龄(企业的年龄为0), 区域,失信内容, 公布日期, 公布执行单位, 创建日期, 更新日期
企业信用信息公示系统
- 访问http://www.gsxt.gov.cn/corp-query-entprise-info-xxgg-100000.html
- 抓取: 失信人名称, 失信人号码, 年龄(企业的年龄为0), 区域, 失信内容, 公布日期, 公布单位, 类型(个人/企业), 创建日期, 更新日期

实现
- 把抓取的数据, 统一存储到同一个数据库的, 同一张表中.
- 如何去重?
- 对于个人: 根据失信人号码, 检查一下, 如果不存在才插入.
- 对于企业/组织:
- 失信人证件号, 有的是组织机构代码, 有的是信用号, 企业信用信息公示系统的失信人公告有的没有证件号, 所以无法进行准确判断.
- 区域 和 企业名称进行检查, 如果有就重复了, 没有才插入.
百度
scrapy startproject dishonest 创建爬虫项目
数据模型
定义数据模型继承自scrapy.Item的数据模型DishonestItem
1 | class DishonestItem(scrapy.Item): |
分析
通过翻页发起请求,在控制台的All请求下出现了https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6899&query=失信人名单&pn=0&ie=utf-8&oe=utf-8&format=json的目标地址
参数:
- resource_id=6899: 资源id, 固定值
- query=失信人名单: 查询内容, 固定值
- pn=0: 数据起始号码
- ie=utf-8&oe=utf-8: 指定数据的编码方式, 固定值
- format=json: 数据格式, 固定值
我们可以根据第一次请求, 获取到总的数据条数, 生成所有页面的URL.
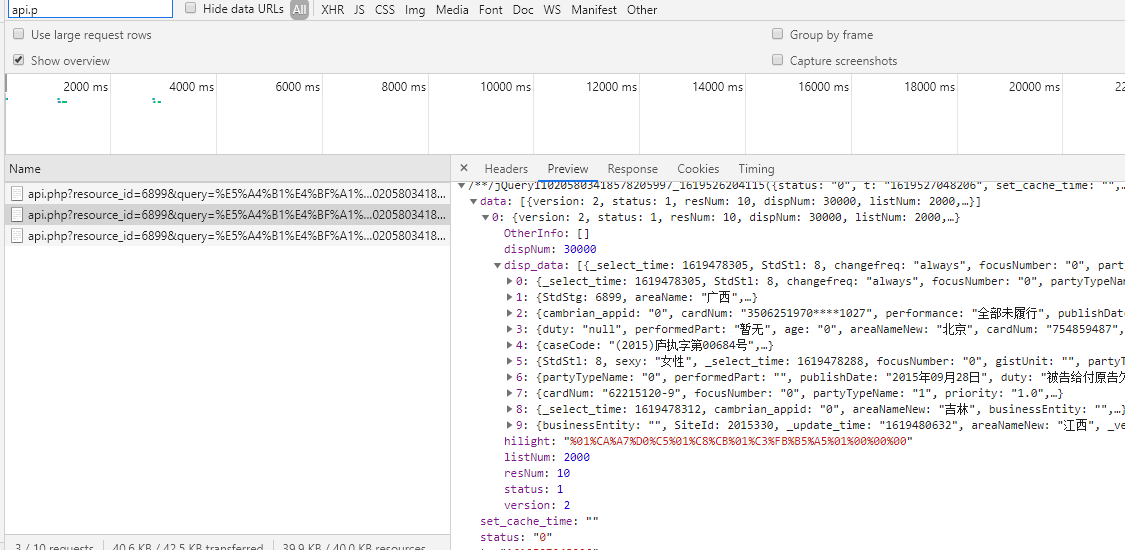
demo
1 | url = 'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=6899&query=失信人&pn=10&rn=10&ie=utf-8&oe=utf-8' |
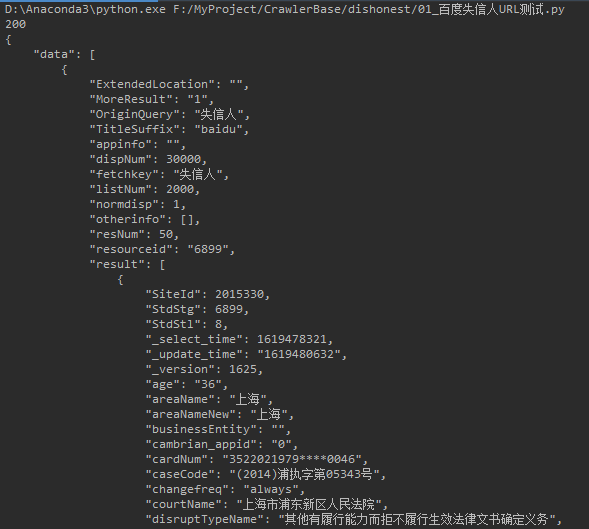
爬虫实现
- 设置默认请求头, 在
settings.py文件中
1 | DEFAULT_REQUEST_HEADERS = { |
scrapy genspider baidu baidu.com创建爬虫- 分页实现
1 | class BaiduSpider(scrapy.Spider): |
数据存储
- 创建数据库表
1 | -- 创建数据库 |
- 在settings中配置数据库信息
1 | # 配置MYSQL |
- 使用pipeline存储数据到mysql
1 | class DishonestListPipeline(object): |
随机User-Agent反反爬
- 在settings.py中添加USER_AGENTS列表
1 | USER_AGENTS = [ |
- 实现随机User-Agent下载器中间件
1 | class RandomUserAgent(object): |
- settings.py中开启中间件
1 | # 开启下载器中间件 |
代理IP反反爬
实现代理IP下载器中间件,在settings.py中开启, 并配置重试次数,继爬虫基础篇之IP代理池实现的动态IP代理池启动用于本次失信人抓取。
1 | class ProxyMiddleware(object): |
配置代理池中间件及重试次数(毕竟免费ip不稳定)
1 | # 开启下载器中间件 |

国家企业信用公示系统
继JS逆向之国家企业信用信息公示系统Cookie传递完成了cookie的逆向分析,本文利用Cookie的实现逻辑,在scrapy中实现公示系统的爬虫入库。
scrapy genspider gsxt gsxt.gov.cn 创建爬虫
准备起始URL, 打印响应内容
1 | class GsxtSpider(scrapy.Spider): |
修改原来的随机User-Agent, 和随机代理的下载器中间件类, 如果是公示系统爬虫直接跳过.
1 | # 随机User-Agent下载器中间件 |
定制cookie
为了实现代理IP, User-Agent, cookie信息生成, 绑定和重用,实现步骤如下:
步骤:- 实现生成cookie的脚本
- 用于生成多套代理IP, User-Agent, Cookie信息, 放到Redis
- 实现公示系统中间件类,
- 实现
process_request方法, 从Redis中随机取出Cookie来使用, 关闭页面重定向. - 实现
process_response方法, 如果响应码不是200 或 没有内容重试 - 在setting.py文件件中配置, 开启该下载器中间
- 实现
- 实现生成cookie的脚本
实现生成cookie的脚本
- 创建
gen_gsxt_cookies.py文件, 在其中创建GenGsxtCookie的类 - 实现一个方法, 用于把一套代理IP, User-Agent, Cookie绑定在一起的信息放到Redis的list中
- 随机获取一个User-Agent
- 随机获取一个代理IP
- 获取request的session对象
- 把User-Agent, 通过请求头, 设置给session对象
- 把代理IP, 通过proxies, 设置给session对象
- 使用session对象, 发送请求, 获取需要的cookie信息
- 把代理IP, User-Agent, Cookie放到字典中, 序列化后, 存储到Redis的list中
- 实现一个run方法, 用于开启多个异步来执行这个方法.
注: 为了和下载器中间件交互方便, 需要在settings.py中配置一些常量.
- 创建
1 | def push_cookie_to_redis(self): |
settings.py中配置信息
1 | # 定义cookie的键 |
定制中间件
步骤- 实现process_request方法, 从Redis中随机取出Cookie来使用, 关闭页面重定向.
- 实现process_response方法, 如果响应码不是200 或 没有内容重试
1 | class GsxtCookieMiddleware(object): |
在setting.py文件件中配置中间件
1 | DOWNLOADER_MIDDLEWARES = { |
完善爬虫
- 解析页面中的城市名称和id, 构建公告信息的URL
- 解析失信企业公告信息
1 | class GsxtSpider(scrapy.Spider): |

