篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
代理池介绍
由众多ip组成提供多个稳定可用代理IP的ip池。
当我们做爬虫时,最常见的反爬手段就是IP反爬,当同一个IP访问网站超出频控限制,将会被限制访问,那么代理IP池应运而生。资金充足的情况下个人建议还是付费ip代理池,比较免费ip时效性低,且难以维护。
本文将介绍通过requests库多线程抓取多个免费代理ip网站数据落库mongo后并动态维护保证IP高度可用,以API形式暴露接口获取代理IP的解决方案。
爬取流程
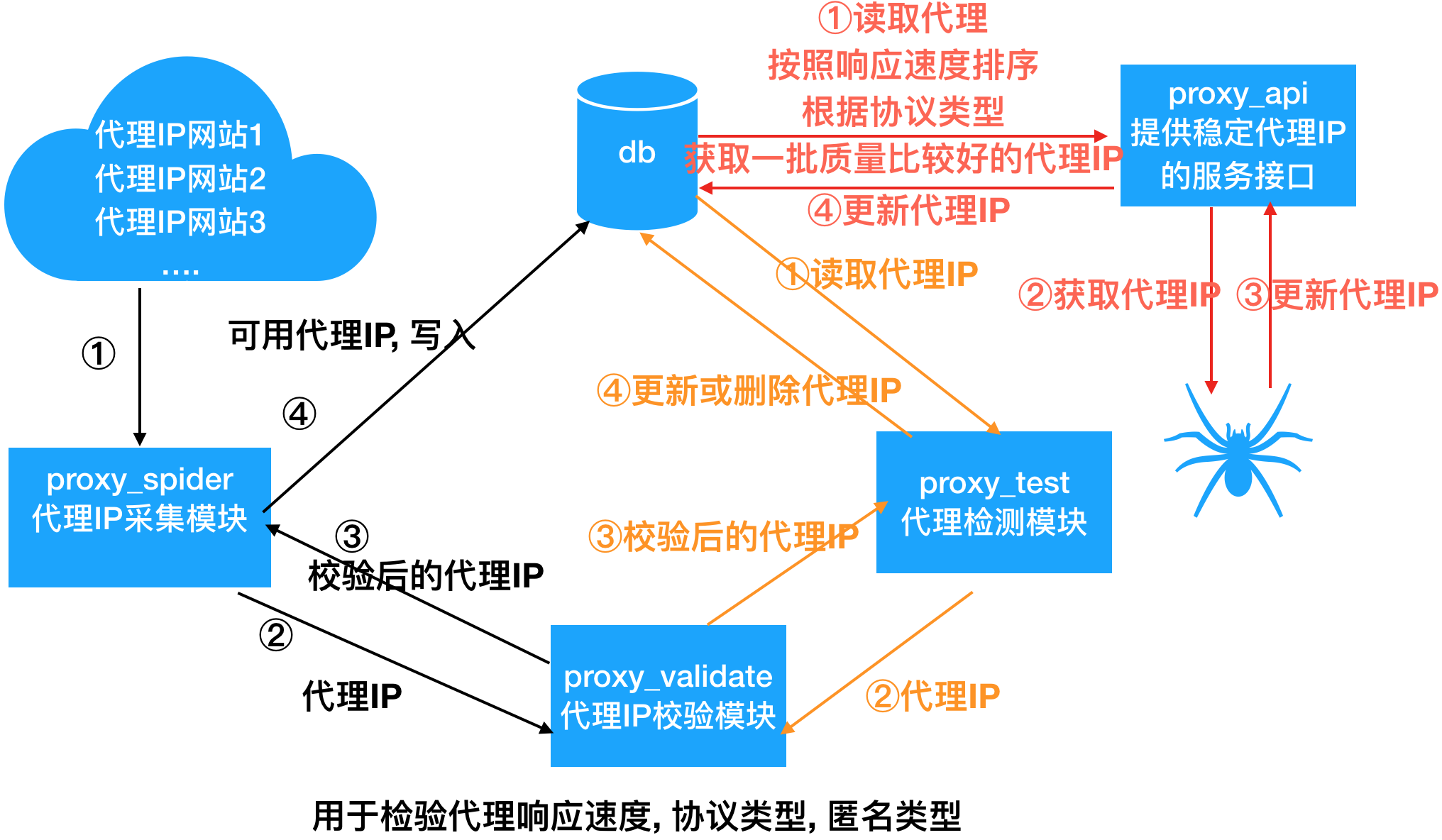
- 代理IP采集模块: 采集代理IP -> 检测代理IP ->如果不可用用, 直接过滤掉, 如果可用, 指定默认分数 -> 存入数据库中
- 代理IP检测模块: 从数据库中获取所有代理IP -> 检测代理IP -> 如果代理IP不可用用, 就把分数-1, 如果分数为0从数据库中删除, 否则更新数据库, 如果代理IP可用, 恢复为默认分值,更新数据库
- 代理API模块:从数据库中高可用的代理IP给爬虫使用;
模块
爬虫模块
从代理IP网站上采集代理IP ,对抓取的ip进行校验(获取代理响应速度, 协议类型, 匿名类型), 并存储到数据库中。
校验模块
网站上所标注的响应速度,协议类型和匿名类型是不准确的,通过httpbin.org进行检测,获取指定代理的响应速度, 支持的协议以及匿名程度。
数据库模块
使用MongoDB来存储代理IP并实现对代理IP的增删改查操作。
检测模块
定时从数据库读取所有的代理IP,对代理IP进行逐一检测, 开启多个协程, 以提高检测速度,如果该代理不可用, 就让这个代理分数-1, 当代理的分数到0了, 就删除该代理; 如果检测到代理可用就恢复为满分。
API模块
根据协议类型和域名获取多个随机的高质量代理IP,根据代理IP不可用域名, 告诉代理池这个代理IP在该域名下不可用, 下次获取这个域名的代理IP时候, 就不会再获取这个代理IP了, 从而保证代理IP高可用性。
其他模块
数据模型
代理IP的数据模型, 用于封装代理IP相关信息, 比如ip,端口号, 响应速度, 协议类型, 匿名类型,分数等。
程序入口
代理池提供一个统一的启动入口
工具模块
日志模块: 用于记录日志信息
http模块: 用于获取随机User-Agent的请求头
配置文件
用于默认代理的分数, 配置日志格式, 文件, 启动的爬虫, 检验的间隔时间 等。
实战
思路1:依据流程图,逐步实现各个模块,当需要依赖其他模块时,暂停当前模块,开发其他模块功能,实现完毕再回头开发联调。
思路2:先实现不依赖其他模块的基础模块,再逐步实现具体的功能模块,比如爬虫模块, 检测模块, 代理API模块。
这里我们选择思路2实现爬虫代理IP池,因为思路1适合个人完成,不适合分工合作,且不易维护,思路跳来跳去,必须逻辑清晰。
数据模型domain
settings.py 中 定义MAX_SCORE = 50, 表示代理IP的默认最高分数
1 | class Proxy(object): |
日志模块log
导入settings中日志配置信息,如下
LOG_LEVEL = logging.DEBUG # 默认等级
LOG_FMT = ‘%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s: %(message)s’ # 默认日志格式
LOG_DATEFMT = ‘%Y-%m-%d %H:%M:%S’ # 默认时间格式
LOG_FILENAME = ‘log.log’ # 默认日志文件名称
1 | class Logger(object): |
请求模块http
返回随机请求头和随机User-Agent,对抗反爬
1 | # 1. 准备User-Agent的列表 |
校验模块httpbin_validator
- 检查代理IP速度 和 匿名程度;
- 代理IP速度: 就是从发送请求到获取响应的时间间隔
- 匿名程度检查:
- 对
http://httpbin.org/get或https://httpbin.org/get发送请求 - 如果 响应的
origin中有’,’分割的两个IP就是透明代理IP - 如果 响应的
headers中包含Proxy-Connection说明是匿名代理IP - 否则就是高匿代理IP
- 对
- 检查代理IP协议类型
- 如果
http://httpbin.org/get发送请求可以成功, 说明支持http协议 - 如果
https://httpbin.org/get发送请求可以成功, 说明支持https协议
- 如果
1 | def check_proxy(proxy): |
数据库模块mongo_pool
- 在
init中, 建立数据连接, 获取要操作的集合, 在del方法中关闭数据库连接 - 提供基础的增删改查功能
- 提供代理API模块使用的功能
- 实现查询功能: 根据条件进行查询, 可以指定查询数量, 先分数降序, 速度升序排, 保证优质的代理IP在上面.
- 实现根据协议类型 和 要访问网站的域名, 获取代理IP列表
- 实现根据协议类型 和 要访问网站的域名, 随机获取一个代理IP
- 实现把指定域名添加到指定IP的disable_domain列表中.
1 | class MongoPool(object): |
爬虫模块base_spider
- 在base_spider.py文件中,定义一个BaseSpider类, 继承object
- 提供三个类成员变量:
- urls: 代理IP网址的URL的列表
- group_xpath: 分组XPATH, 获取包含代理IP信息标签列表的XPATH
- detail_xpath: 组内XPATH, 获取代理IP详情的信息XPATH, 格式为: {‘ip’:’xx’, ‘port’:’xx’, ‘area’:’xx’}
- 提供初始方法, 传入爬虫URL列表, 分组XPATH, 详情(组内)XPATH
- 对外提供一个获取代理IP的方法
- 遍历URL列表, 获取URL
- 根据发送请求, 获取页面数据
- 解析页面, 提取数据, 封装为Proxy对象
- 返回Proxy对象列表
1 | # 1. 在base_spider.py文件中,定义一个BaseSpider类, 继承object |
具体爬虫实现proxy_spiders
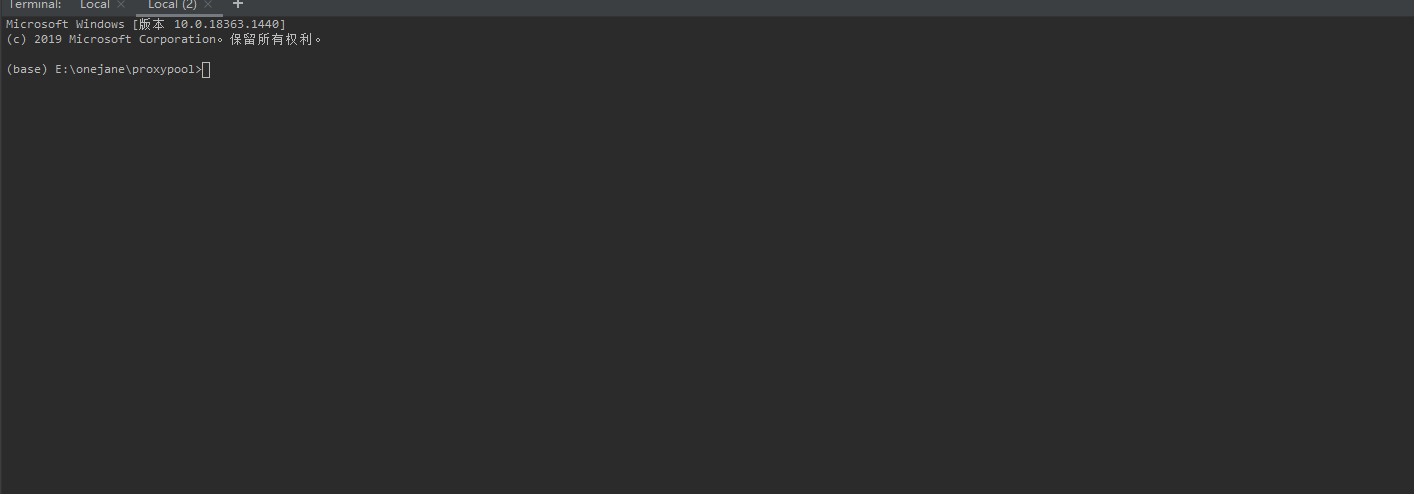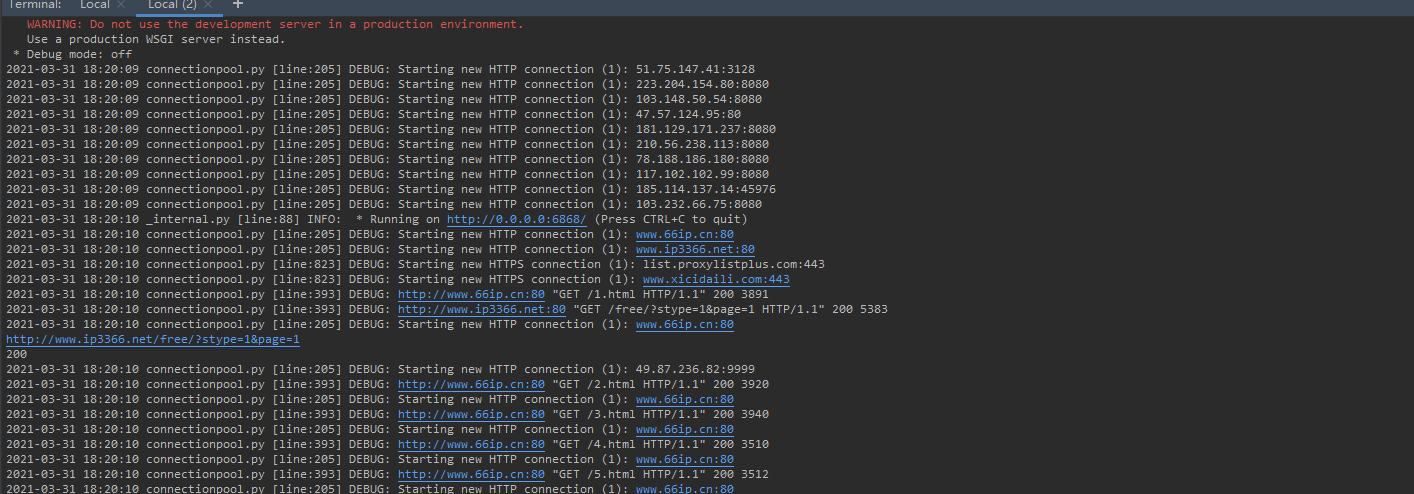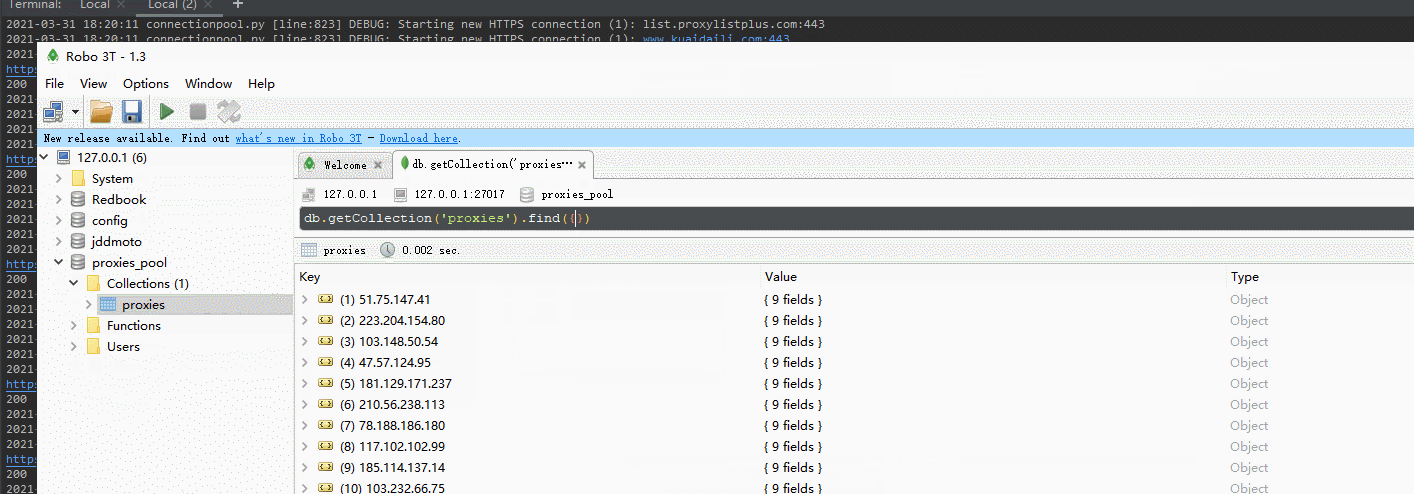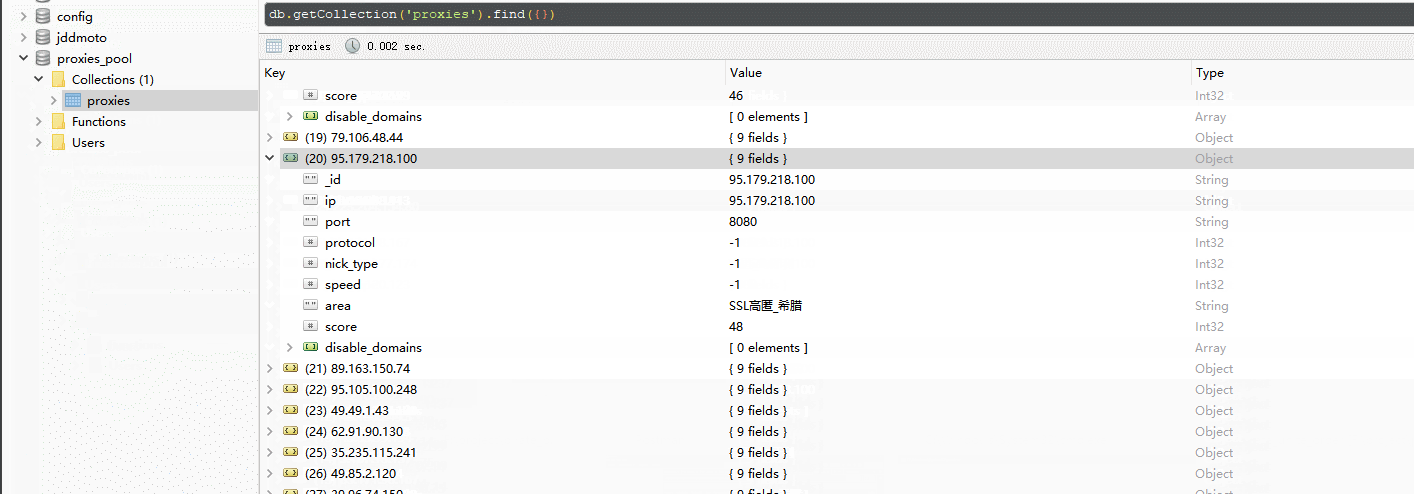
实现西刺代理爬虫:http://www.xicidaili.com/nn/1定义一个类,继承通用爬虫类(BasicSpider)提供urls, group_xpath 和 detail_xpath
实现
ip3366代理爬虫:http://www.ip3366.net/free/?stype=1&page=1- 定义一个类,继承通用爬虫类(BasicSpider)
- 提供urls, group_xpath 和 detail_xpath
实现
快代理爬虫:https://www.kuaidaili.com/free/inha/1/- 定义一个类,继承通用爬虫类(BasicSpider)
- 提供urls, group_xpath 和 detail_xpath
实现
proxylistplus代理爬虫:https://list.proxylistplus.com/Fresh-HTTP-Proxy-List-1- 定义一个类,继承通用爬虫类(BasicSpider)
- 提供urls, group_xpath 和 detail_xpath
实现
66ip爬虫:http://www.66ip.cn/1.html- 定义一个类,继承通用爬虫类(BasicSpider)
- 提供urls, group_xpath 和 detail_xpath
- 由于66ip网页进行js + cookie反爬, 需要重写父类的
get_page_from_url方法
访问http://www.66ip.cn/1.html 时返回一堆js,并不返回具体ip信息,通过逐步增加请求头中的Cookie时发现真正生效的Cookie为_ydclearance,控制台打开Preserve log发现页面第一次1.html做了跳转,历史请求中都没有出现_ydclearance的cookie,第二次请求1.html时已经携带了_ydclearance说明该cookie已经不是服务端响应生成,而是由客户端js生成。
一开始我们访问http://www.66ip.cn/1.html 时返回一堆js,执行这段js,就是用来生成_ydclearance的。那么分析这段js本身做了加密,js中通过定义函数jp并调用后,由于qo=eval,那么等同于最终调用了eval(po),真正js在 “po” 中。
通过正则提取
jp(107)调用函数方法, 以及函数内容function jp(WI) { var qo, mo="" ...,通过将替换eval拿到返回的真实js
2
func_str = func_str.replace('eval("qo=eval;qo(po);")', 'return po')执行js并将返回作为Cookie添加到请求头中
2
3
4
5
context.execute(func_str)
context.execute('code = {};'.format(result[0][0]))
cookie_str = re.findall("document.cookie='(.+?); ", context.code)[0]
headers['Cookie'] = cookie_str
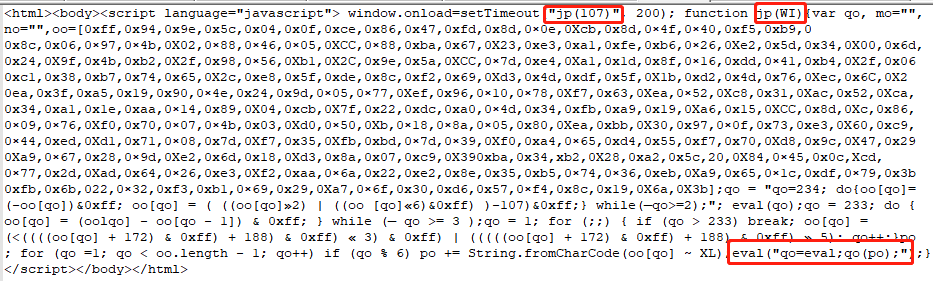
1 | class XiciSpider(BaseSpider): |
运行爬虫模块run_spiders
- 创建RunSpider类
- 提供一个运行爬虫的
run方法 - 根据配置文件信息, 加载爬虫, 把爬虫对象放到列表中
- 遍历爬虫对象列表, 获取代理, 检测代理(代理IP检测模块), 写入数据库(数据库模块)
- 使用异步来执行每一个爬虫任务
- 每隔一定的时间, 执行一次爬取任务
settings配置RUN_SPIDERS_INTERVAL作为爬虫运行时间间隔的配置, 单位为小时
1 | class RunSpider(object): |
检测模块proxy_test
- 创建ProxyTester类,检查代理IP可用性, 保证代理池中代理IP基本可用
- 提供一个
run方法, 用于处理检测代理IP核心逻辑- 从数据库中获取所有代理IP
- 遍历代理IP列表
- 检查代理可用性
- 如果代理不可用, 让代理分数-1, 如果代理分数等于0就从数据库中删除该代理, 否则更新该代理IP
- 如果代理可用, 就恢复该代理的分数, 更新到数据库中
- 为了提高检查的速度, 使用异步来执行检测任务
- 把要检测的代理IP, 放到队列中
- 把检查一个代理可用性的代码, 抽取到一个方法中; 从队列中获取代理IP, 进行检查; 检查完毕, 调度队列的task_done方法
- 通过异步回调, 使用死循环不断执行这个方法,
- 开启多个一个异步任务, 来处理代理IP的检测; 可以通过配置文件指定异步数量
- 使用
schedule模块, 每隔一定的时间, 执行一次检测任务- 定义类方法
start, 用于启动检测模块 - 在
start方法中- 创建本类对象
- 调用run方法
- 每间隔一定时间, 执行一下, run方法
- 定义类方法
setting.py 文件, 检查代理IP可用性间隔时间的配置
RUN_SPIDERS_INTERVAL = 2 # 修改配置文件, 增加爬虫运行时间间隔的配置, 单位为小时
TEST_PROXIES_ASYNC_COUNT = 10 # 配置检测代理IP的异步数量
TEST_PROXIES_INTERVAL = 2 # 配置检查代理IP的时间间隔, 单位是小时
1 | class ProxyTester(object): |
API模块proxy_api
- 创建
ProxyApi类,为爬虫提供高可用代理IP的服务接口 - 实现初始方法
- 初始一个Flask的Web服务
- 实现根据协议类型和域名, 提供随机的获取高可用代理IP的服务
- 可用通过
protocol和domain参数对IP进行过滤 protocol: 当前请求的协议类型domain: 当前请求域名
- 可用通过
- 实现根据协议类型和域名, 提供获取多个高可用代理IP的服务
- 可用通过
protocol和domain参数对IP进行过滤
- 可用通过
- 实现给指定的IP上追加不可用域名的服务
- 如果在获取IP的时候, 有指定域名参数, 将不在获取该IP, 从而进一步提高代理IP的可用性.
- 实现run方法, 用于启动Flask的WEB服务
- 实现start的类方法, 用于通过类名, 启动服务
settings中配置PROXIES_MAX_COUNT配置获取的代理IP最大数量; 这个越小可用性就越高; 但是随机性越差
1 | class ProxyApi(object): |
启动入口main
- 定义一个run方法用于启动动代理池,开启三个进程, 分别用于启动
爬虫,检测代理IP,WEB服务- 定义一个列表, 用于存储要启动的进程
- 创建
启动爬虫的进程, 添加到列表中 - 创建
启动检测的进程, 添加到列表中 - 创建
启动提供API服务的进程, 添加到列表中 - 遍历进程列表, 启动所有进程
- 遍历进程列表, 让主进程等待子进程的完成
- 在
if __name__ == '__main__':中调用run方法
1 | def run(): |
完整源码请关注微信公众号:ReverseCode,回复:爬虫基础

