篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
执行流程
python并不像java这类高级语言需要将文件编译为机器码交给虚拟机执行,而是由python虚拟机一条条地将py语句解释运行,故而称之为解释型语言。
python先将py文件编译成字节码,交给字节码虚拟机后,虚拟机从编译得到的PyCodeObject对象在当前的上下文环境逐条执行字节码指令,完成整个程序的执行流程。
字节码在python虚拟机程序里对应的是PyCodeObject对象, .pyc文件是字节码在磁盘上的表现形式。
例如:在python test.py过程中会将test.py进行编译成字节码并解释执行,当test.py中加载了其他模块,如import urllib2,python会将urllib2.py进行编译成字节码,生成urllib2.pyc,并重新对字节码解释执行。加载模块时,当.py和.pyc同时存在时,优先运行.pyc文件,若.pyc文件比.py编译时间早,执行流程也会优先重新编译.py文件并更新.pyc文件。
.pyc文件通过内置模块py_compile来编译生成test.pyc,或者通过python -m test.py生成test.pyc
GIL
由于物理上的科技发展,各CPU厂商在核心频率上已经被多核CPU所取代,为了更有效的利用多核处理器的性能,就出现了多线程的编程技巧,又因为Python GIL的存在让Python虚拟机在进行运算时无法有效利用多核心,几乎只能单线程处理任务,所以将任务并行化,分散到多个线程或多个进程的实现和GIL本身的存在是天生冲突的矛盾。
首先,GIL不是python的特性,是实现python解析器(CPython)时的语法标准,并不是python的特性,类似的还有JPython等就没有GIL,但是CPython是大部分环境下默认的Python执行环境,自然而然CPython==python,自然而然GIL成为的python天生的缺陷。
当多核CPU出现在市场的时候,python为了支持多线程,首要解决的就是线程之间的数据完整性和数据同步性,GIL应运而生,简单粗暴的为线程加上了一把大锁,后起之库们默认都接受了这种实现方案,省去考虑额外线程间的内存锁和同步操作,导致大量的三方库都极度依赖GIL来实现线程安全。GIL这把全局排他锁,是多线程处理的致命伤,效率极底,因为python的线程就是C的一个pthread,通过操作系统的调度算法调度,为在调度过程中各线程平均利用CPU的时间,python会计算已执行的代码量,达到阈值强制释放GIL锁,触发一次操作系统的调度。
任何一个线程在唤起时可以成功获取到GIL,但是多核CPU上,release和acquire几乎没有间隔,导致其他核上的线程被唤醒时,主线程已经再次拿到GIL,导致被唤醒的其他线程只能白白浪费CPU时间,眼睁睁看着另一个线程拿个GIL快乐的执行,当达到切换时间后进入待调度状态,再次唤醒再次等待,恶性循环。
多线程方案
multiprocessing
一定程度弥补了thread库由于GIL锁导致低效的缺陷,完整的实现了一套thread接口,但是只是使用了多进程而本身不是多进程,原理上每个进程有自己独立的GIL,不会出现进程间的GIL争抢,但是增加了线程间数据通讯和同步的麻烦,由于不同进程间无法看到对方的数据状态,只能在主线程声明一个队列,通过队列的实现解决数据本身的问题,无疑徒增的代码的开发与维护成本。
concurrent
提供了多线程ThreadPoolExecutor和多进程ProcessPoolExecutor两种并发模型。
- 计算密集型任务
永远最多只能榨干单核CPU,如果需要提升效率,必须通过ProcessPoolExecutor fork出多个子进程来分担计算任务。 - IO密集型任务
CPU使用效率极低,虽然使用多线程加倍CPU使用率,但是还远远到不了饱和(100%)的地步,在单核心可以应付整体计算的前提下,自然是应该选择资源占用少的模式,也就是多线程模式。主线程是通过队列将任务传递给多个子线程的。一旦主线程将任务塞进任务队列,子线程们就会开始争抢,最终只有一个线程能抢到这个任务,并立即进行执行,执行完后将结果放进Future对象就完成了这个任务的完整执行过程。
concurrent的线程池有个重大的缺陷,那就是任务队列是无界的。如果队列的生产者任务生产的太快,而线程池消费太慢处理不过来,任务就会堆积。如果堆积一直持续下去,内存就会持续增长直到OOM,任务队列里堆积的所有任务全部彻底丢失。
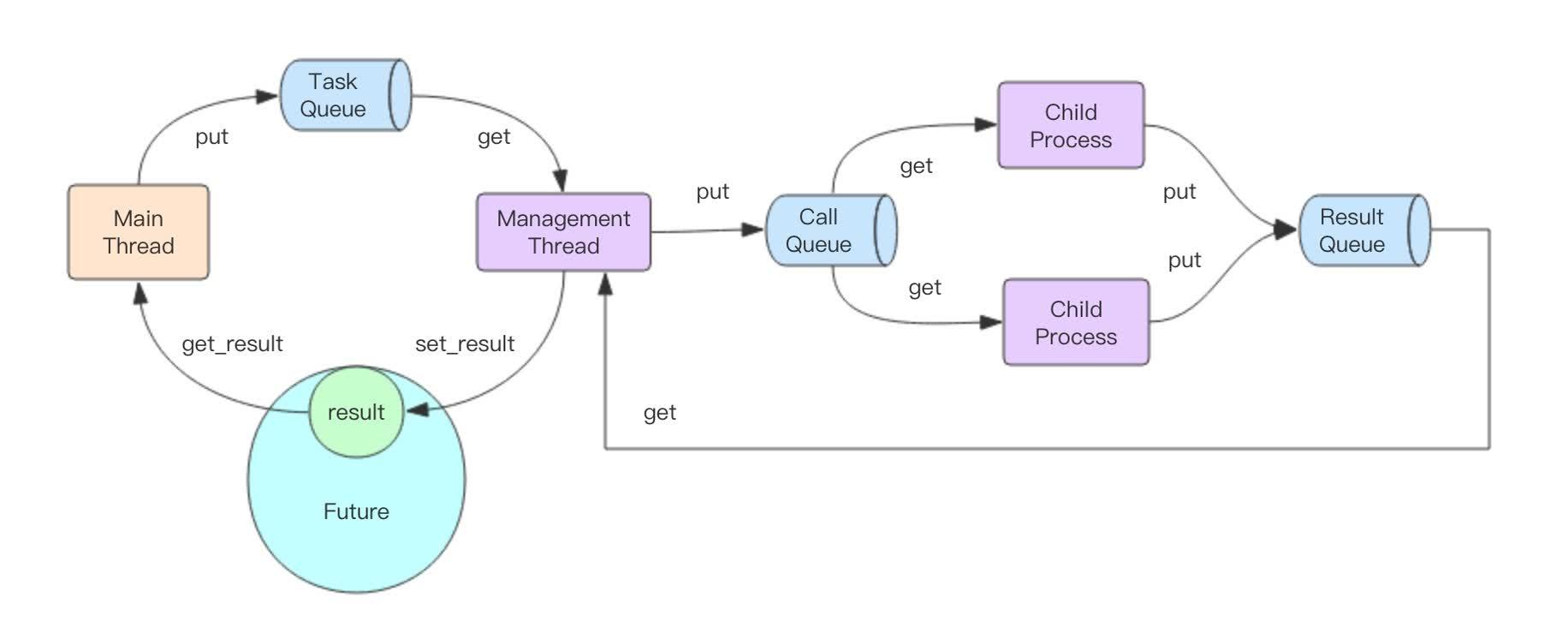
- 主线程将任务塞进TaskQueue(普通内存队列),拿到Future对象
- 唯一的管理线程从TaskQueue获取任务,塞进CallQueue(分布式跨进程队列)
- 子进程从CallQueue中争抢任务进行处理
- 子进程将处理结果塞进ResultQueue(分布式跨进程队列)
- 管理线程从ResultQueue中获取结果,塞进Future对象
- 主线程从Future对象中拿到结果
进程池模型中的跨进程队列是用multiprocessing.Queue实现的。它使用无名套接字sockerpair来完成的跨进程通信,socketpair和socket的区别就在于socketpair不需要端口,不需要走网络协议栈,通过内核的套接字读写缓冲区直接进行跨进程通信。multiprocessing.Queue是支持双工通信,数据流向是父子双向,只不过在concurrent的进程池实现中只用到了单工通信。CallQueue是从父到子,ResultQueue是从子到父。
当父进程要传递任务给子进程时,先使用pickle将任务对象进行序列化成字节数组,然后将字节数组通过socketpair的写描述符写入内核的buffer中。子进程接下来就可以从buffer中读取到字节数组,然后再使用pickle对字节数组进行反序列化来得到任务对象,这样总算可以执行任务了。同样子进程将结果传递给父进程走的也是一样的流程,只不过这里的socketpair是ResultQueue内部创建的无名套接字。
实战
doutula
上文讲到通过分析页面元素分页抓取doutula表情包并保存图片的的案例,由于网络请求结果返回往往比IO存储图片要快,接下来通过多线程的方式实现在IO相对较慢的前提下使用多线程处理存储图片。核心代码如下:
1 | def main(page): |
guazi
同时执行多个线程的确可以提高程序效率,但并非线程越多越好,相对计算机而言,线程越多越吃资源,成百上千个线程可能直接瘫痪。故而多线程在运行时,设置最大线程锁,设置最大线程同时允许处理任务,多线程threading使用Semaphore(无上限)或BoundedSemaphore(初始设置最大值), 如果release调用检查计数器的值是否超过了计数器最大值则出ValueError 实现并发限制。
例如:通过semaphore信号量可以利用内置计数器来控制同时运行线程的数量,启动线程(消耗信号量)内置计数器会自动减一,线程结束(释放信号量)内置计数器会自动加一;内置计数器为零,启动线程会阻塞,直到有本线程结束或者其他线程结束为止;
以下我们对瓜子二手车数据进行多线程抓取,并保存到csv中。
分析
当我们访问第一页时,https://www.guazi.com/su/buy/o1
当我们访问第二页时,https://www.guazi.com/su/buy/o2
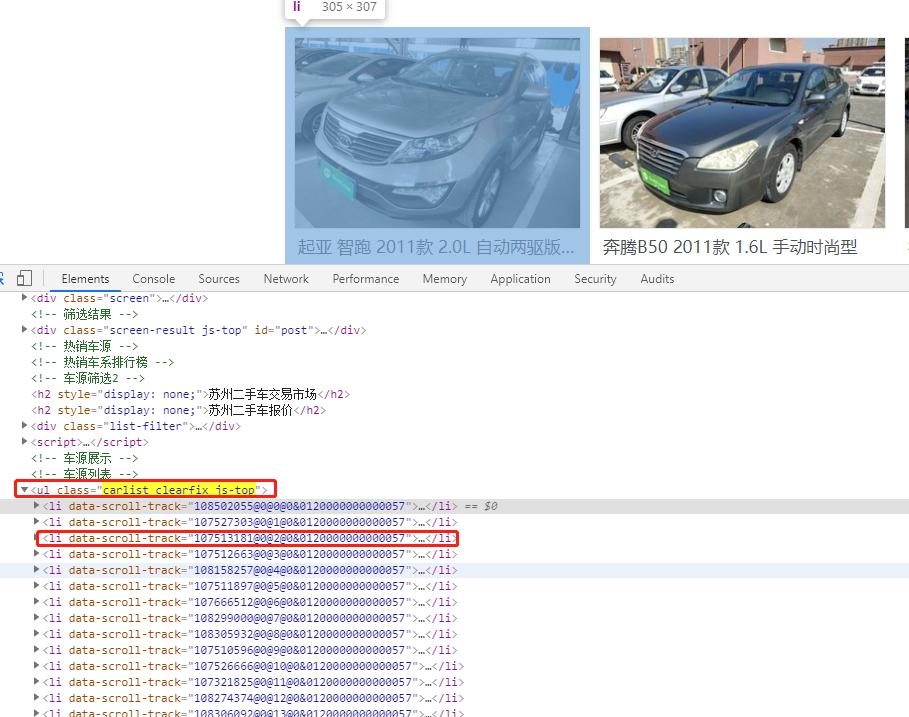
以此类推,不难得出分页数据以start_url = 'https://www.guazi.com/su/buy/o'+str(i)形式拼接,i为页码数,根据页面控制台的Elements分析所有的数据都存在于含有类carlist clearfix js-top的ul节点下的所有li节点下,我们可以通过解析得到html代码转化为bs4库的BeautifulSoup对象,利用BeautifulSoup的api获取这些li节点的元素属性,解析拿到类型,年份,里程,售价,具体BeautifulSoup语法出门右转见中文文档。
1 | def get_data(html): |
get_data拿到所有的数据属性后,接下来通过含有信号量的多线程方式调用封装好的download_pics方法批量抓取图片。
1 | # 定义最多10个线程同时允许 |
完整源码请关注微信公众号:ReverseCode,回复:爬虫基础

