篇幅有限
完整内容及源码关注公众号:ReverseCode,发送 冲
题目
http://match.yuanrenxue.com/match/3
抓取下列5页商标的数据,并将出现频率最高的申请号填入答案中
抓包
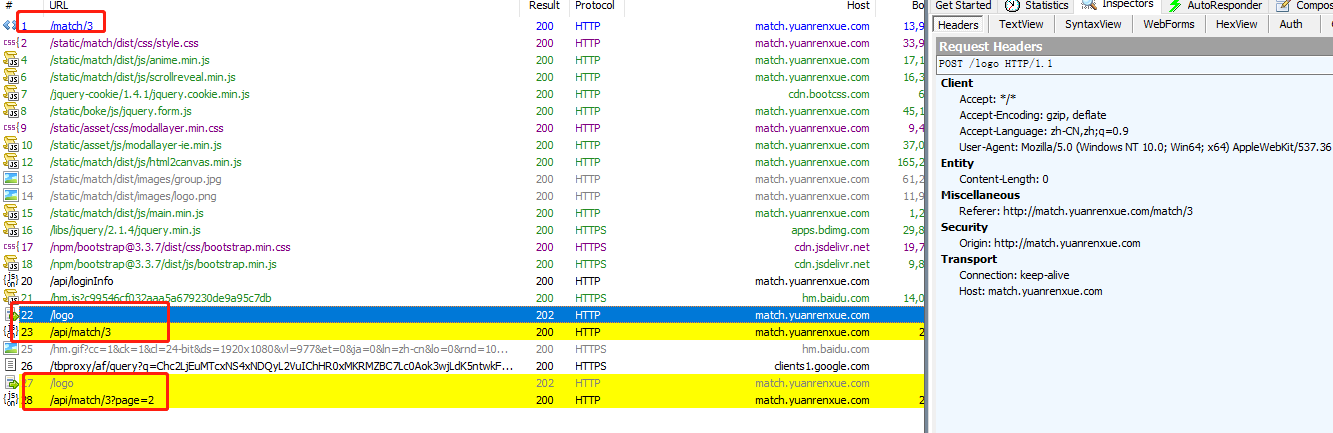
分析
http://match.yuanrenxue.com/match/3 请求原始网页后请求一堆js/css,并没有携带cookie和特殊的返回
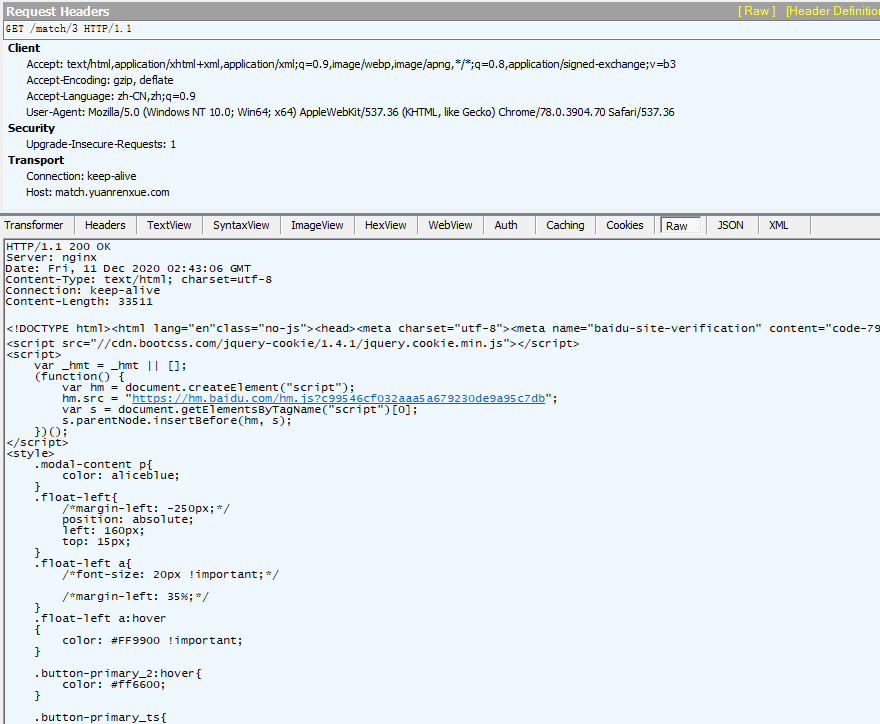
http://match.yuanrenxue.com/logo 每次请求页数的时候都会先请求logo并set了一个cookie,说明cookie是从服务器返回的
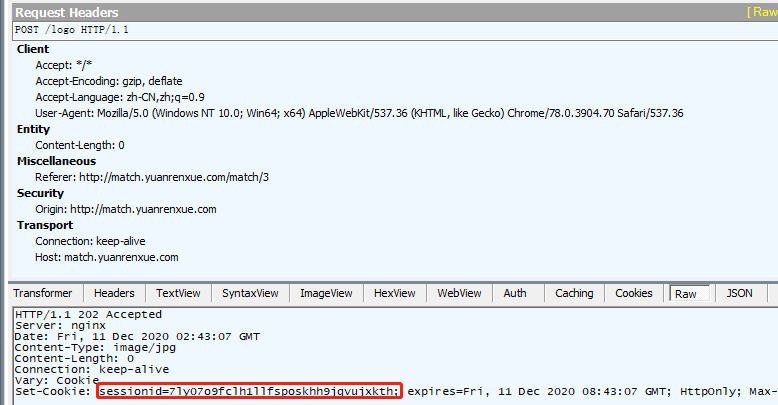
http://match.yuanrenxue.com/api/match/3 请求返回页面json数据,携带logo返回的cookie
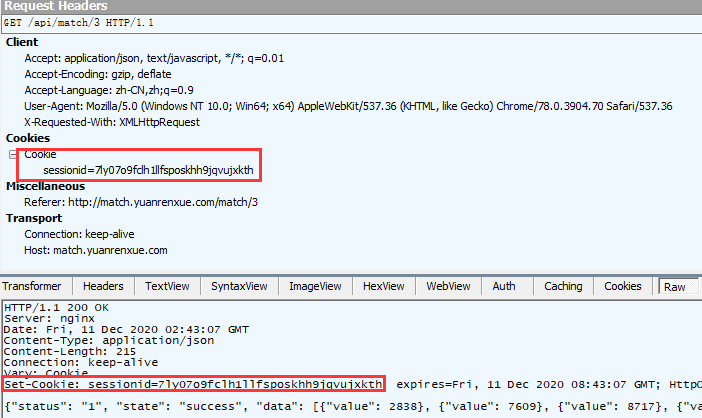
没有带cookie不能访问http://match.yuanrenxue.com/api/match/3
使用请求头加引号.py 将fiddler的请求头包上
请求头加引号.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import re
old_headers ='''
Connection: keep-alive
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Referer: http://match.yuanrenxue.com/match/3
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: sessionid=7ly07o9fclh1llfsposkhh9jqvujxkth
'''
pattern = '^(.*?):[\s]*(.*?)$'
headers = ""
for line in old_headers.splitlines():
headers += (re.sub(pattern,'\'\\1\': \'\\2\',',line)) + '\n'
print(headers[:-2])
|
加上cookie使用python请求抓取返回一堆js代码,因为cookie是由服务器生成的,所以这一段返回的js没有意义
1
2
3
4
5
6
7
8
9
10
11
12
13
| headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'yuanrenxue.project',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'sessionid=7ly07o9fclh1llfsposkhh9jqvujxkth'
}
url = 'http://match.yuanrenxue.com/api/match/3'
res = requests.get(url=url, headers=headers)
print(res.text)
|
爬虫
规律:请求完logo后再请求api则正常返回,同理请求第二页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| session = requests.session()
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'yuanrenxue.project',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
session.headers = headers
url_logo = 'http://match.yuanrenxue.com/logo'
res = session.post(url_logo)
print(res, res.cookies)
url = 'http://match.yuanrenxue.com/api/match/3?page=1'
res = session.get(url=url)
print(res.text)
|

